MetaTool > Help > Extraction > Remove Text
060-650 MetaTool Extraction Edit – Remove Text
The Remove text rule is very useful when you need to extract particular words, names, codes or numbers from documents that contain redundant text. For example, names are often written after a label like in: “Full name: Alfred Pennyworth”. However, we only need the name and drop the label for further processing of the invoice.
You first define an OCR extraction rule first to hold the full text of a scanned document in an index field we typically call Text Block or Full Text. Next, you would define a Find Line with Mask / Words rule to filter the full text and only keep the relevant lines. Next, you remove the unwanted text in that line with the Remove text rule.
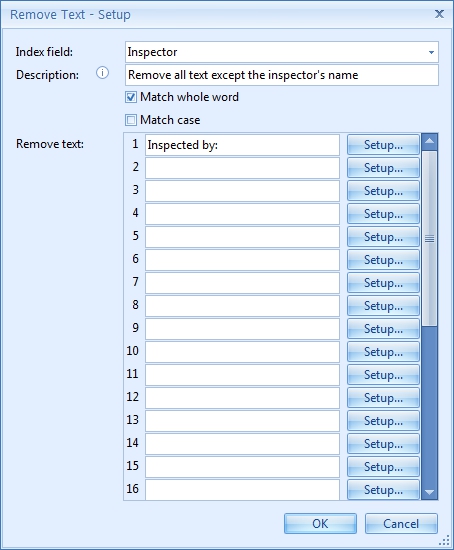
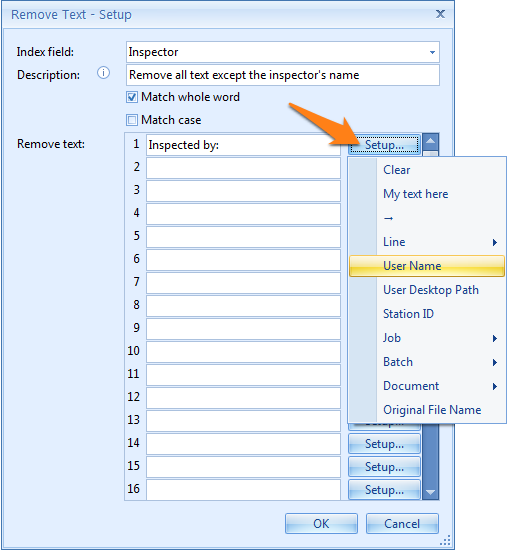
For example, to extract the Inspector’s name from a Report, you can search for the line containing “Inspected“ with the Find Line with Mask / Words rule and then remove the “Inspected by: ” text using the Remove text rule.
01 Remove text- Add Rule
Remove text is defined in the MetaTool Extract tab.
Press the Add button and select Edit – Remove text to add the edit rule.
02 Remove text – Setup
In our example, we will make use of the CB MetaTool Keyword Doc Sep job. This job is automatically installed when you install CaptureBites MetaTool.
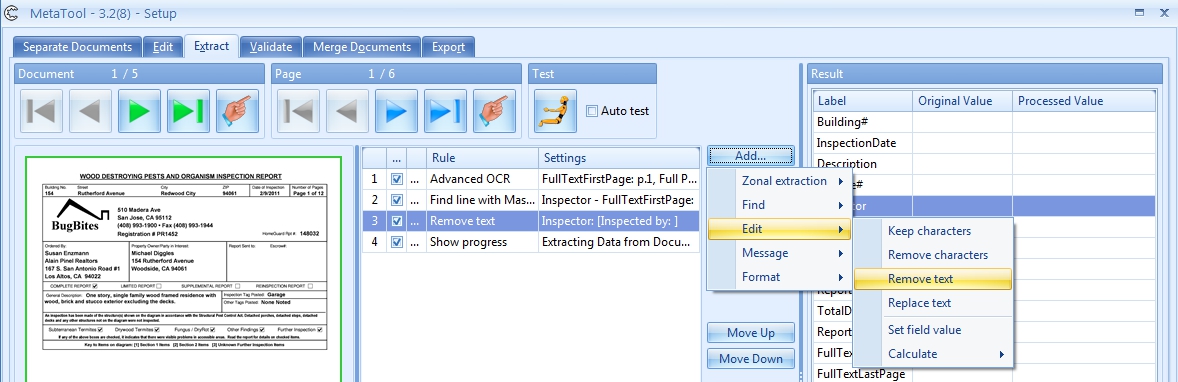
We will use these image samples and we want to extract the Inspector from the bottom left corner.




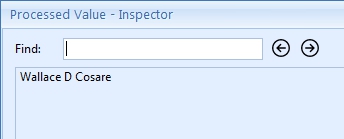
The result looks like this:
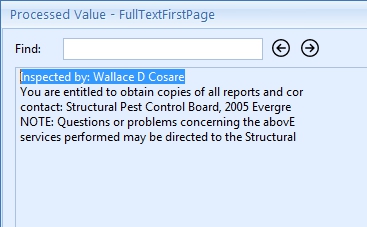
The result after this rule looks like this:
Optionally enter a description.
For example: with Match case disabled and when removing the word “apple”, it would remove “APPLE”, “apple” and “Apple”. If Match case is active, only the word “apple” would be removed and “APPLE” and “Apple” would remain untouched.
In our case, we only want to remove the text “Inspected by:“.
For example, assume the name looks like this:
