MetaTool > Help > Extraction > Replace Text
060-660 MetaTool Extraction Edit – Replace Text
With the MetaTool Replace text rule, you can clean up text or correct OCR mistakes and make it easier to extract correct data. It’s frequently combined with a Find Word or Find Line rule.
The Replace text rule is very useful when you need to extract data that needs to be changed for further processing or for making it easier to find the required data in the text.
A classic example is a supplier invoice. All invoices have an invoice date, number, total amount etc. but the data isn’t always uniform. Dates, for example, can be written as March 14, 2007, 03-14-2007, 03/14/2017, etc.. With the Replace text rule, we can alter the data to one specific format.
You first define an OCR extraction rule to hold the full text of a scanned document in an index field we typically call Text Block or Full Text. Next, you would define a Replace text rule to adjust the text to prepare for extraction in the next rule.
Finally, you would define a Find Word with Mask / Words to extract the actual index value you are interested in.
01 Replace text- Add Rule
Replace text is defined in the MetaTool Extract tab.
Press the Add button and select Edit – Replace text to add the Replace text rule.
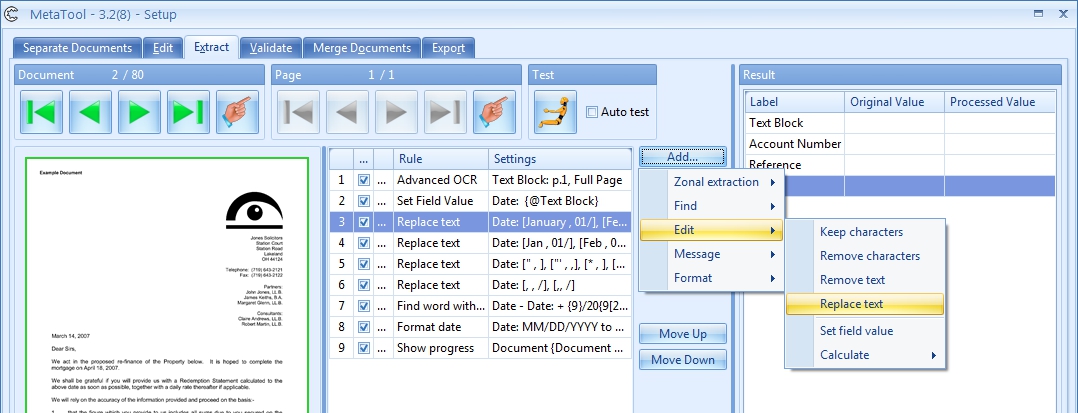
02 Replace text – Setup
In our example we will make use of the CB MetaTool Floating Data job. This job is automatically installed when you install CaptureBites MetaTool.
From below image samples (US formatted dates) we want to extract the date. Sometimes the date is written as “March 14, 2007”, “JAN 8, 07” or in MM/D/YYYY format. We want to change all these different formats to a standard MM/DD/YYYY format.



In our example, we will explain how to change the long, fully written date to our required format. The other formats are set up in a similar way.
To edit the text containing the date, select the index field to hold the extracted data.
In this case we select the index field “Date”.
Optionally enter a description.
03 – Match whole word: only replaces text exactly matching the defined word(s). When disabled, it will also replace the specified text if it’s a part of a word.
For example: when disabled and when replacing “apple” with “orange”, it would also replace it in other words containing “apple”, like “pineapple” would become “pineorange”. If the option is enabled, the rule will only replace the word “apple” if it is a whole word and ignore words like “pineapple”.
04 – Match case: only replaces text that exactly matches the defined word(s) case. When disabled, it will replace the specified word(s), regardless the case.
For example: when enabled and when replacing the word “January, it would replace only the word “January” and ignore words like “january”, and “JANUARY”.
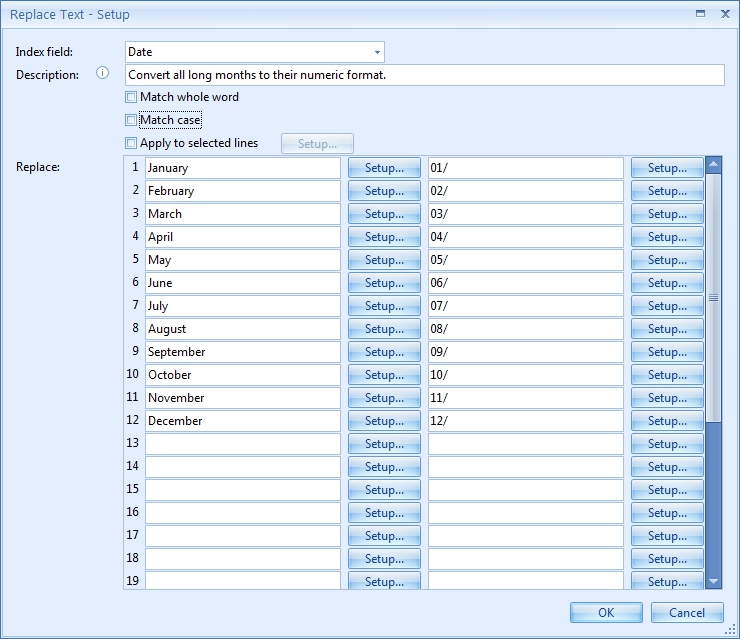
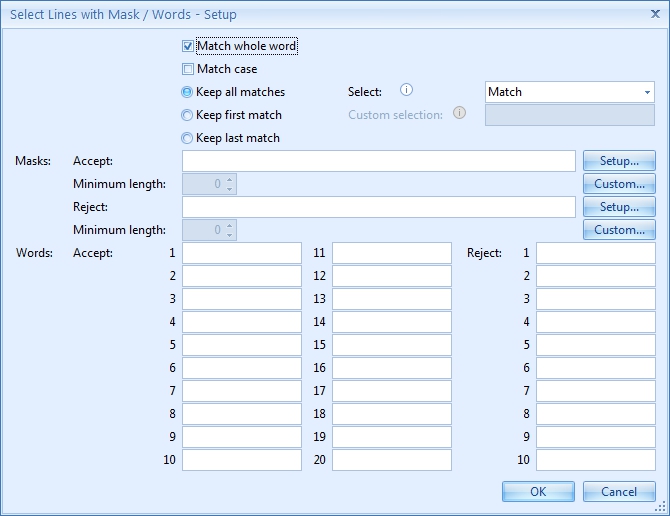
05 – Setup of Apply to selected lines: This is an advanced option and the purpose of it is to only apply the replace rule to certain lines containing (or not containing) specific words and/or mask(s). For example replace all the “–” with “/” symbols in lines containing the word “date”.
Enable the Apply to selected lines option and press the Setup button to edit.
06 – Replace: Here you enter the text you want the rule to replace. Enter the words you want to replace in the left column. In the right column, you enter the values that the words in the left column will be replaced with. You can define up to 30 words to be replaced in a single rule. If you want more than 30 words to be replaced, you simply add another Replace text rule.
In our case, we will replace the months in long name format with their numeric format.
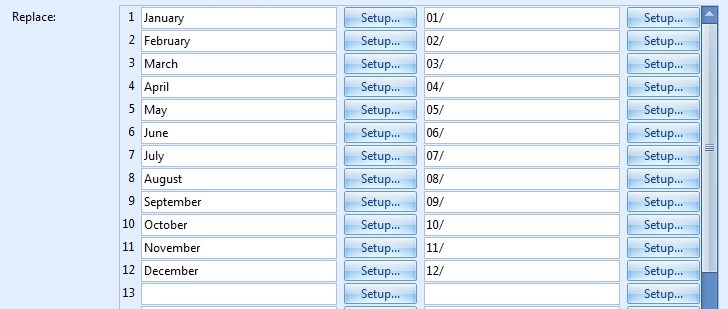
07 – Setup of Replace: By pushing the Setup button, you can select different system and index values to compose your text. In our example we just enter the months followed by a space in the left column and the corresponding numeric month value followed by a slash in the right column.
Important: Please, be aware that the replacement of the defined words will occur in the sequence the words are entered in the replace rule.
For example, if you first replace “Jan” with “01/” and then “January” with “01/” the rule will not work correctly. Such rule would convert a date like “Jan 8” to “01/8” just fine. But a date like “January 8” would become “01/uary 8”. It is important in our example that the longest month formats are replaced first, followed by the shorter month format. So first replace “January” with “01/” and only after that replace “Jan” with “01/”.
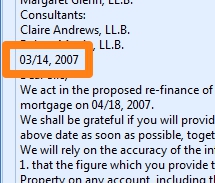
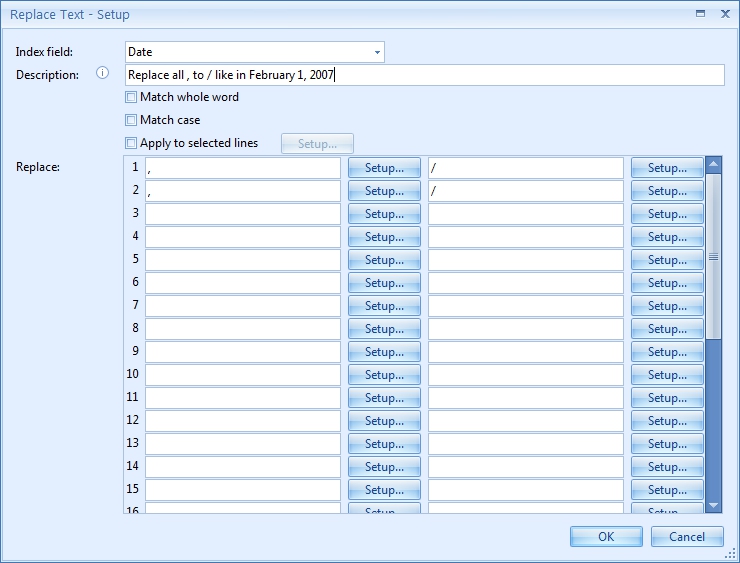
Next, we change the last part of the date format to convert the “, ” (comma and space).
We just add another Replace text rule to change the “, “ (comma and space) to a “/” symbol:
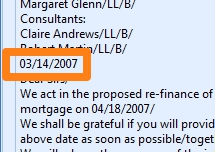
Finally, with a Find word with Mask / Words rule, we filter the full text and only keep the relevant date.
The final result will look like this:
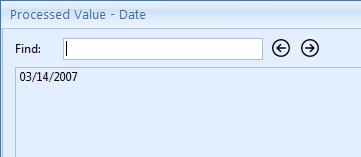
If you want to be extra sure that the date is valid, add a Format date rule.
TIP: Sometimes, the OCR engine will recognize a 1 as an l (lower case L) or a 0 as an O (upper case letter O).
If this happens regularly for your type of documents, simply use a Replace text rule to replace the l (lower case L) with a 1 and the upper case letter O with 0 correcting these OCR errors automatically.
If you know that you are only extracting a number, it doesn’t matter that other words would be affected with this Replace text rule. If you want to use the text for other purposes, first copy the text in another index field with a Set field value rule. Then apply the replace rule to the copied value and correct the OCR errors. In that way, your original text stays intact and can be used to extract other data.