Is this an l or an I?
We often get questions about the best font type to design a header sheet or form that will be used for OCR reading. OCR stands for Optical Character Recognition, the process to convert an image into searchable / editable computer text and required to extract data automatically from scanned images with a product such as MetaTool or MetaServer.
The most challenging for any OCR technology is to distinguish between characters that look similar. For example the OCR engine needs to distinguish the letter O from the digit 0 and an l from an I. And to be fair without any context even we have difficulty making the difference between an l (lowercase L) and an I (uppercase i) with the font used on this web page.
We tried a range of standard Windows fonts and we found out that the standard Tahoma font works best. Tahoma is a modern looking sans serif (no curls) proportionally spaced font. Proportionally spaced means that for example the letter i takes less space than the letter w which makes text more readable and also more compact.
Tahoma is present on any Windows system and the main reason that this font works so well is that there is enough difference between look-a-like characters which make the OCR engine interpret each character correctly even without any context.
Have a look for yourselve, these are some classic examples of characters printed with Tahoma that could cause confusion if printed with another font:
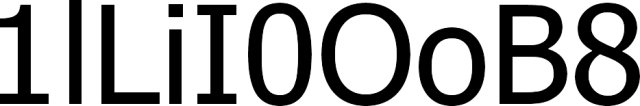
The Tahoma font type shows enough difference between each of these characters that confusion is avoided.
The popular Arial font for example does not show any difference between an l (lowercase L) and an I (uppercase i) which does not make it a good candidate for your design. As long as there is context, the OCR engine will manage well with the Arial font but without context, substitution errors may occur.
PDF Test Document
Below PDF file, is designed with the Tahoma font type. Although font size 9 still works fine, we recommend to use a font size between 12 and 14 when scanning in 300 DPI if only to reduce confusion caused by image noise generated by dust in the scanner or stains on the documents.
Using very large font sizes like 24 and higher don’t add any reliabiltiy, they just take more space.
 Loading...
Loading...
Avoid different font sizes on a single line
The very first step to convert an image to text with OCR is to convert pixels into characters blocks als known as character segmentation. Obviously, font size and text alignment play an important role in this process.
To help the OCR technology extract text correctly, avoid mixing different font size on a single line like in:

In other words, always use the same font size for the label and the variable data following the label.
Avoid mistakes in alignment like in:
![]()
Even more subtle shifts than in above example and alignment mistakes may cause imperfect OCR results.
We have workarounds for most of these issues on existing documents which cannot be changed but if you design a form or header sheet from scratch it is better to take into account above tips to obtain maximum readability.