MetaServer > Help > Validate > Validate Date and Time
040-040 MetaServer Validate – Validate Date and Time
With MetaServer’s Validate Date and Time rule, you can let an operator correct or verify a Date field if the value doesn’t have the correct format, is not in the specified date range, etc.
You can also enter and format the date field value by drawing a rectangle around the date using the Select Text Tool.
In our example, we will make use of the “CB – INVOICES US” workflow. This workflow is automatically installed with CaptureBites MetaServer.
We need to extract and validate the Invoice Date of each document, which is typically located on the first page:

Depending on the vendors, the format of dates on invoices can have a lot of variation.
For example, a date like the 2nd of February, 2017 can be written as:
– “February 6, 2017”
– “Feb 06, 17”
– In numeric US formats like “2/6/2017”, “02-06-2017”
– In European formats like “6/02/2017” or “06-02-17”, etc.
The same can be said for time codes. A time code could be written as “15:25:02”, “03:25 PM”, “15h25m02s”, etc.
Another example is a full date that consists of a date AND time code, like in “2018-06-18 15:25:02”
During extraction, we will normalize all these different date formats to a consistent standard date format like DD-MM-YYYY (Europe) or MM-DD-YYYY (US). In that way, during Validation, the Operator will be presented dates in a consistent format regardless of the original format on the document.
To learn more about how to extract and format dates, please have a look at the Extract rules related to the Invoice Date extraction in the “CB – INVOICES US” demo workflow.
Validate Date and Time rules are defined as part of a MetaServer Validate action.
If you are not familiar with adding a Validate Action to your workflow, please refer to our Validate action help guide.
After adding a Validate action to your workflow or opening the setup of an existing one, you can add a Validate Date rule. In the Validate action, press the Add button and select Date and Time.
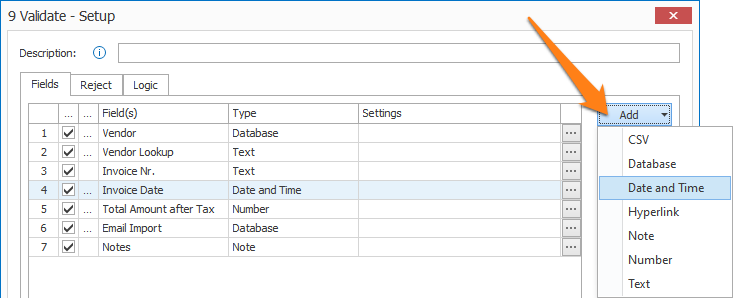
TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to zoom in.
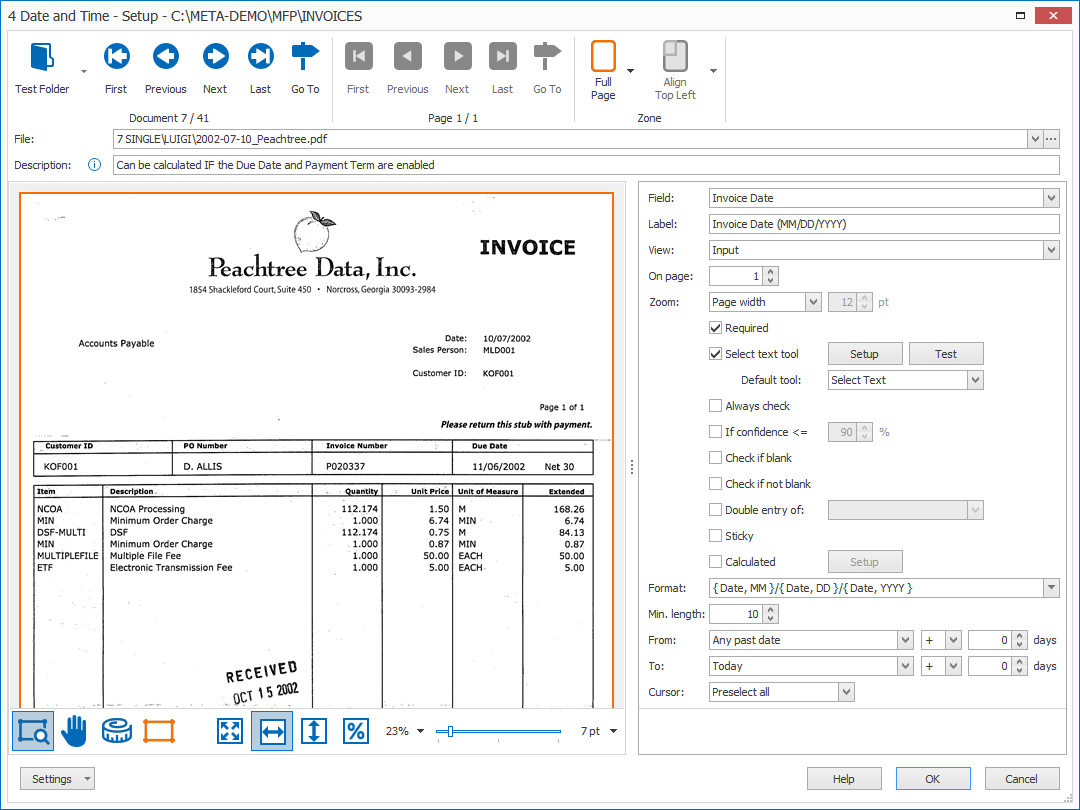
First, add a description to your rule. Then, select a field with the extracted value. In this case, we select the field “Invoice Date”.
01 – Zone: in the Validate Date and Time setup window’s toolbar, you will find two Zone tools to specify the highlighted zone on the page where your field value is typically located.
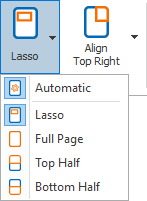
The purpose is to draw the attention to the correct part of the page to assist the operator to find the data on the page:
1) Automatic: this automatically jumps to the page where the data that was found by your previous Extract rules, frames it with a pink border and and highlights the zone (1 cm / 0.5 inch around the pink frame).
This helps to draw the Operator’s attention to the exact location on the page.
Only if the Extract rules failed to extract the data, the defined highlight zone will be used (Lasso, Full Page, Top Half or Bottom Half). By default, the “Automatic” highlighting is enabled.
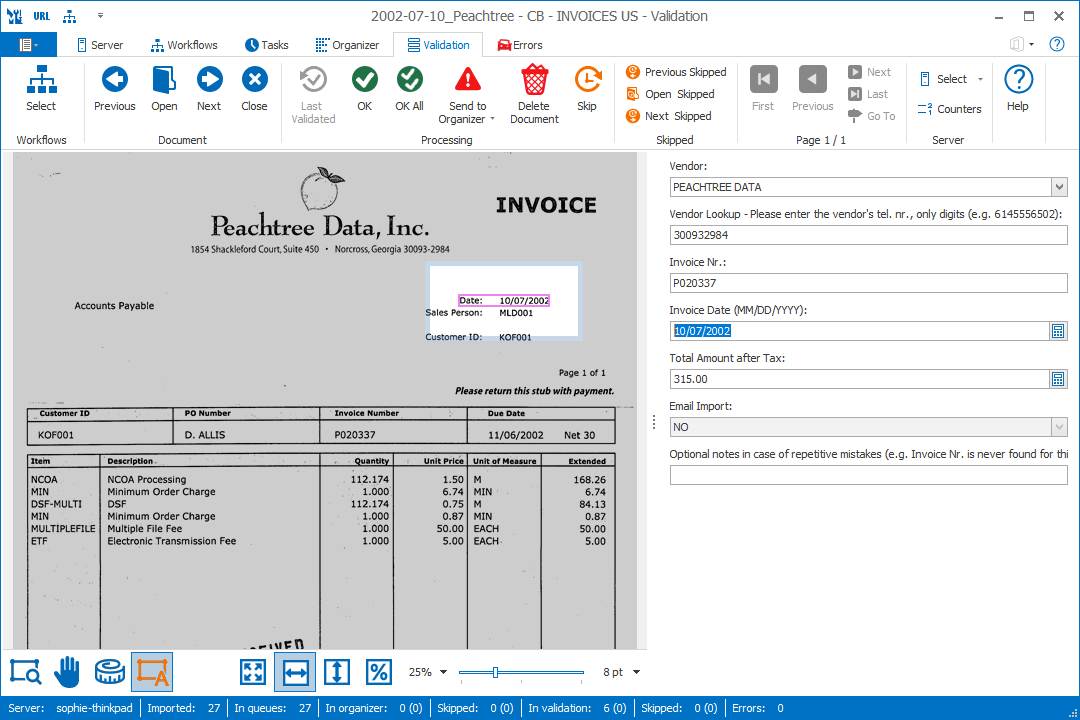
The Invoice Date was automatically extracted and shows its exact location.
2) Lasso / Full Page / Top Half / Bottom Half: you can choose what part should be highlighted on the page when the operator navigates in the validation field if the data was not automatically extracted.
You can highlight the full page, the top or bottom half of the page or you can specify a custom zone with the Lasso option. You can do this by drawing a zone with the select tool which will be framed with an orange border.
The area around that highlighted zone will be dimmed in the validation viewer.
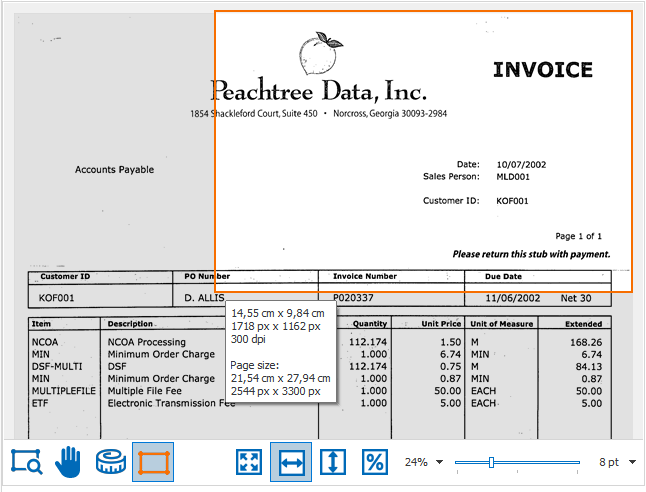
The area around the highlighted zone will be dimmed in the validation viewer.
TIP: while drawing, you can see the zone’s dimensions in cm/inches (depending on your regional settings) and in pixels. You’ll also find the page’s resolution in DPI and the page size in cm/inches and pixels.
We recommend you scan your documents with a resolution of 300 DPI for the best OCR result and compact file size.
This is what the result looks like in the validation viewer when a value was not automatically extracted:
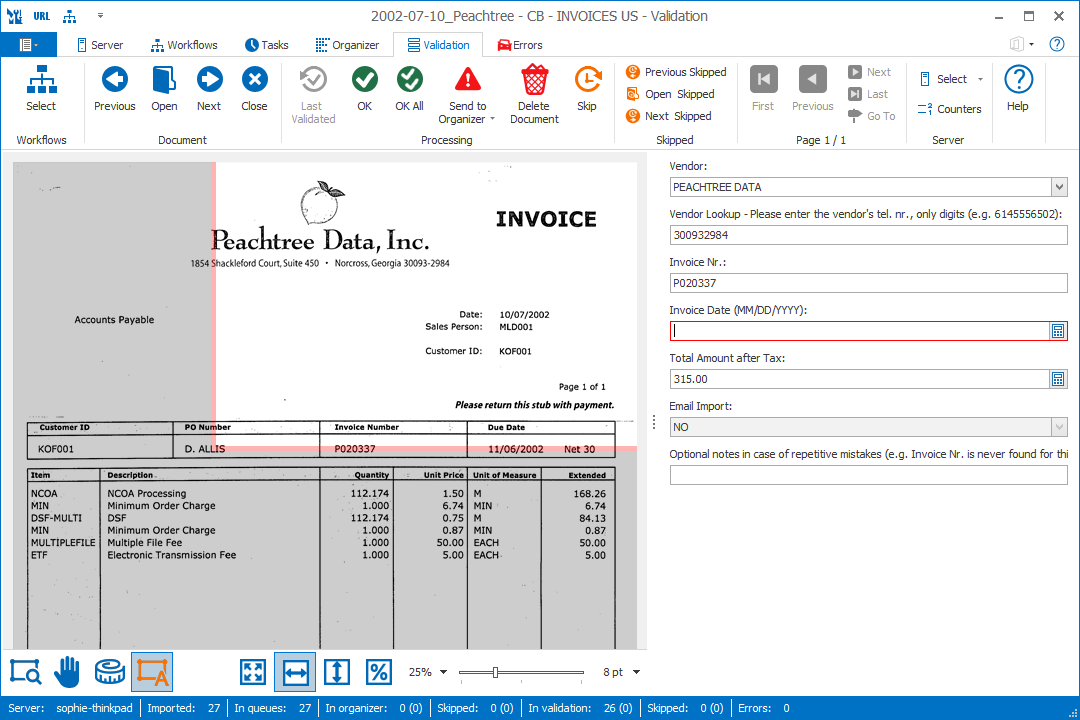
The Total Amount after Tax was not automatically extracted and shows the highlighted zone instead.
02 – Align: when your documents vary in size or have mixed orientations (portrait and landscape mixed together), you can align your highlight zone in relation to any of the 4 corners of the image: the top left or right corner or the bottom left or right corner.
That way, the zone will be positioned correctly on all sizes and orientations.
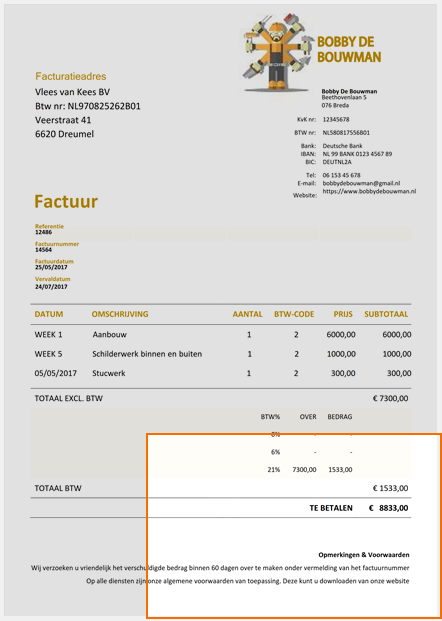
Bottom right alignment of a zone on a portrait-oriented image
Bottom right alignment of a zone on a landscape-oriented image
03 – Label: the label displayed during validation above your current field’s input box. The default label is the same name as your field, but you can change this to a custom label. For example, the full field name, name with hints, abbreviations, etc.
In the example below, we have set the label to “Invoice Date (MM/DD/YYYY)” to help the operator enter the expected format.
Note: The colon (:) following the label is automatically added.
04 – View: select the view mode of the field when the user navigates in the field:
2) Input (manual navigation): disables highlighting and automatic page loading when there is no automatically extracted data.
The operator will need to navigate to the correct position manually during validation. Only when the value was extracted automatically, the page will be automatically loaded and the value will be highlighted. This is often used when the field value needs to be manually entered and is never in the same position (e.g. the Total Amount on an invoice).
3) Read-Only: this grays out the field value. This only allows the operator to view the extracted field value. The operator cannot change the value.
It still highlights and automatically loads the page where the data was found. If the read-only field does not hold any data, the viewer will stay in its current position.
05 – On page: set the page number to where the field value is most likely located. This page will be loaded when the value was not extracted automatically. Otherwise, the page where the value was extracted from will be loaded.
The default is page 1.
For example:
– Enter 1 for the 1st page
– Enter -1 for the last page
– Enter -2 for the page before the last page
– Etc.
If a document does not contain the specified page, it will load the last page. For example, validating page 3 on a 2-page document will show page 2.
06 – Zoom: set the Zoom to the preferred level when the operator navigates in the field.
You can choose between:
1) Whole page: shows the whole page in the validation viewer. This can be useful if you want to show the location of the field value in context of the whole page.
2) Page width: fits the page horizontally in the validation viewer and focuses automatically onto the part where the extracted value is located.
This option is most often used on smaller displays. It gives you a good overview of the page while still being very readable.
3) Page height: fits the page vertically. This can be useful when validating landscape-oriented page.
4) 100%: shows the page without scaling. This option is most commonly used on a large HD monitor with the same resolution as the scanned pages (typically 300 DPI).
5) Font size: zooms the page to a size so that normal text on the page is shown in the specified font size.
6) Zone: the viewer will automatically zoom in on the result. That means that if the result is only a short text like the report number, the viewer will be completely zoomed in on the number and show it very large in the viewer.
07 – Required: a required field means that a value needs to be present in order to pass validation. Disable this option if the field value can be left blank.
This option is useful when working with critical values like amounts, names that can’t be looked up in a database, etc. It’s also essential to double-check when the document is of very poor quality, or, like in our example case, during a demo.
09 – If confidence is lower then: with this option, you can force the operator to check a field value on the condition that it is below the specified confidence percentage level. If the confidence level is higher than the specified value, then the operator is not required to check the field value.
10 – Check if blank: enable this option to only let the operator check this value if it’s blank. The operator can then accept to keep the field blank or adjust it by entering a new value.
11 – Check if not blank: enable this option to only let the operator check this value if it’s NOT blank. The operator can then check if any adjustments need to be made to the extracted value.
12 – Double entry of: “Double-entry” or “Double-Keying” is a process used by operators when they need to enter important information twice. The two entries are then compared with each other to ensure that they match.
NOTE: the double entry is a 2nd field you’ve created based on the original field (e.g. “Groom’s Occupation (2)”).

When the operator presses ENTER or navigates to the next entry, then the first entry is obfuscated.
This is a safety measure for operator 2 so that they are not tempted to just read the value from the first entry but is forced to look at the document again to enter the second value.
When there is a mismatch, it will prompt a warning and force operator 2 to perform one of the following options:
1) Hit SHIFT+ENTER and the value they entered is accepted despite the difference with operator 1’s value. The cursor would also jump to the next field to validate. This is the case where operator 2 overrules operator 1 and believes operator 1 made a mistake.
2) Hit ALT+ENTER to duplicate operator 1’s value in field 2 and the cursor would jump to the next field to validate. This is the case where operator 2 admits that operator 1 got it right and takes over operator 1’s value.
3) Continue repairing the field value. This is the case where operator 2 realizes that neither his value nor operator’s 1 value is correct. After the operator made any changes and hits ENTER, a mismatch is checked again and we go through the above logic again.
For example, operator 2 entered “DRIVER” while operator 1 entered “TRUCK DRIVER”. As soon as operator 2 hits the ENTER key, operator 2’s value is revealed and a pop-up warns that there is a mismatch:

Only by applying 1 of the 3 options we’ve mentioned, can the loop be broken.
The final output will be operator 2’s values.
13 – Sticky: when enabled, the last entered value is saved and presented automatically as the value for the next document.
Common Use-Cases for a Sticky Value:
1) The operator validates all documents of a box. It introduces the box number when he starts validating the first document, then the box number stays the same for all following documents until he changes it when starting the validation for a new box of documents.
2) The operator enters the contract date for a series of a contracts with the same date. He enters the correct date on the first contract and it stays the same on all following contracts until he changes it again.
The sticky value is stored per station, per workflow and per sticky field.
When the operator closes the Operator Client or Admin client, and opens it again, the last-used value is presented again in the sticky fields.
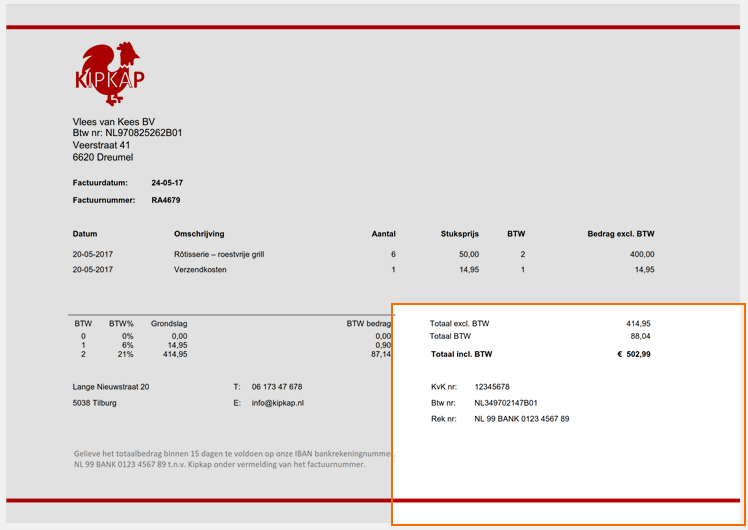
14 – Calculated: enable this option to calculate a date using a date value and a number of days. These can be set in fields or entered manually.
Press the Setup button to open the calculation settings:
The Invoice Date can be calculated by subtracting the Payment Term e.g. 0, 15, 30 days) from the Due Date.
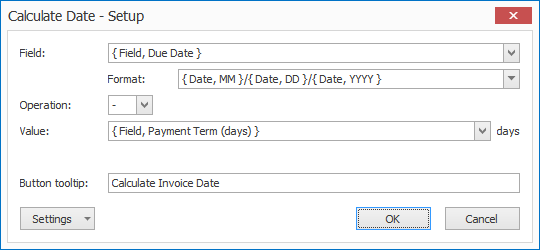
If the automatic extraction of the Due Date or Payment Term failed during extraction, the calculation of the Invoice Date will fail as well.
The operator can correct the missing Due Date or Payment Term in Validation and then automatically calculate the Invoice Date by pressing the calculator button next to the field:
15 – Value settings: here you set up the date limits and format.
1) Format: enter the output format for your date and time value. You can press the drop-down arrow to select different format types to compose your date and time format.
In our case, we specify a typical US “MM/DD/YYYY” date format.
2) Min. Length: if you want to allow shortened versions of your date format, set the minimum length lower than the total length of the date format.
To explain how the minimum length setting works, consider below settings:

12/01/2020:
OK because the number of characters (10) is greater than the defined minimum of 6.
12/1/20:
OK because the number of characters (6) is equal to the defined minimum of 6.
1/1/1:
NOT OK because the number of characters (5) is smaller than the defined minimum length of 6.
December 1, 2020
NOT OK because it does not match the date format.
3) Period (From / To): here you can define a period for the date. Only dates within the defined period are allowed.
You can further customize the period by adding or subtracting a specific number of days. If it needs to be a date within a very specific period, you can use field values for the beginning- and end date.
NOTE: when using dates from fields for the period, the dates need to be in the same format as the current date field. Also, the “From” date always needs to be older than the “To” date.
16 – Cursor: there are 3 possible cursor options:
1) Preselect all (default): when the user navigates in the index field, the value is selected. When the user starts typing, the existing value is completely overwritten with the new value.
2) In front: when the user navigates in the index field, the cursor is positioned in front of the value in the field. When the user starts typing, the new value is inserted in front of the existing value.
When “Cursor in front” is used in combination with the Select Text tool, a space is appended after each Select Text tool result. In that way, you can build a string of words by selecting different words in a text.
3) At end: when the user navigates in the index field, the cursor is positioned after the value in the field. When the user starts typing, the new value is appended at the end of the existing value.

If the operator prefers to use the Zoom tool first to manually zoom in on the value before selecting the text, you may want to choose “Zoom” as the default tool.
Brightness value: default (75)
Brightness value: 140
02 – Drop out: When working with forms with lines and labels in red, green or blue, we can filter these by using the drop out setting.

Drop out: None

Drop out: Red
Thickening value: Default (0)
Thickening value: 2 horizontal, 3 vertical
Most of these settings are related to the OCR and Barcode engine and the processing of the resulting text.
01 – Read barcodes: enable if the field value needs to be extracted from a barcode.
02 – Confidence: characters with a confidence level lower than the set confidence level, will be ignored and not returned in the result. If set to 0, all characters are accepted.
03 – Font size: you can set up a range of acceptable font sizes to only return lines or words containing at least one character within the specified range. You can also choose to only keep the characters matching the selected font size.
04 – Space length: if the result shows too many spaces, like spaces between individual characters, increase this value. If spaces are missing and words start sticking together, decrease the value.
The value is a percentage of the font size of the character following the space. So, spaces in large font type words are automatically considered to be larger than spaces in small text.
05 – Tabs: by default, lines are segmented in multiple word groups that are separated by tabs (long spaces). If you want no tabs at all, press the drop-down button to select the “Remove” option and all the words will be grouped as 1 single word group for each line.
06 – Tab length: define the length of long spaces to convert them to tab characters. If you only want to convert very long spaces to a tab, increase this value. Spaces shorter than the set value will be converted to a single space.
The value is a percentage of the font size of the character following the tab character.
Open the character setup window to exclude or include certain characters during extraction. This can avoid confusion with other characters that never occur in the drawn zone. For example, if the zone only contains a numeric value, disable all alphabetic characters to avoid confusion between 0 and O or 1 and I.
In our example, the operator will draw a rectangle around the report number, so we only select digits.
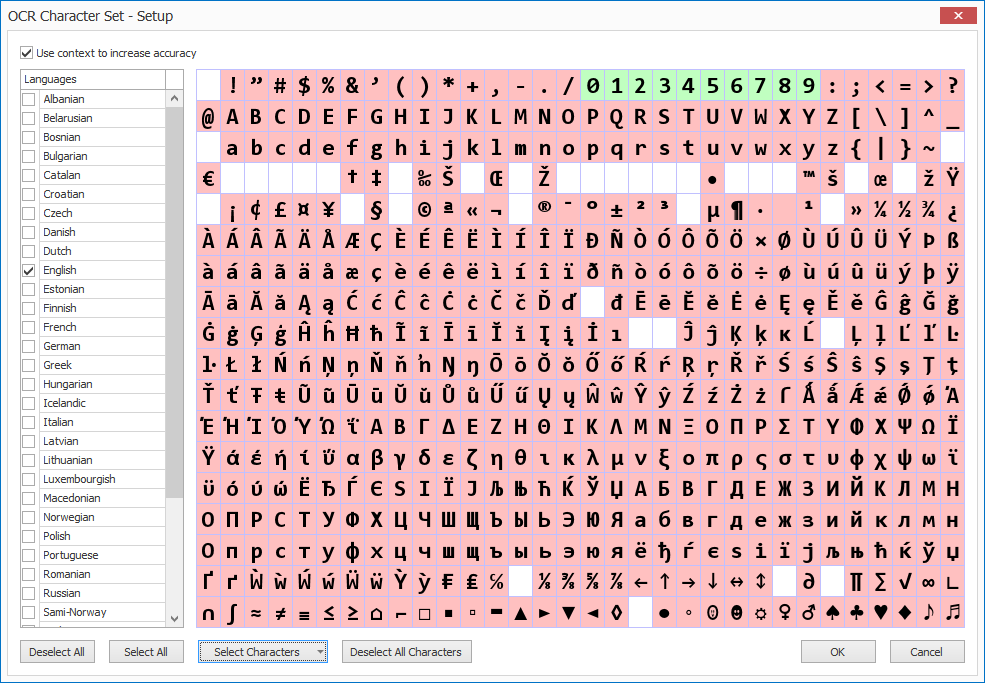
1) Languages: select the primary language(s) of the documents. Selecting a language, will automatically select that language’s character set in the character table.
2) Deselect All Characters: unchecks all characters in the character set. This can be helpful to set up your own custom character set, which is explained in the next step.
3) Select Characters: next to manually selecting / deselecting characters directly in the table, you can press the dropdown button to select a preset of special characters, like digits, uppercase letters, characters for e-mail addresses, etc.
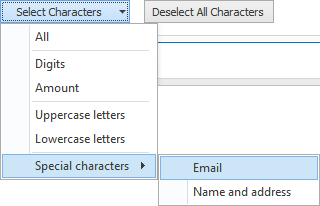
TIP: don’t use the character set as a method to exclude elements from the text.
For example, if you want to extract a code like “123/456/789” and filter out the “/” characters, you may be tempted to just uncheck the “/” character from the character set. But if you do this, the “/” character will most likely be recognized as a 1, which makes the code illegible.
It’s recommended to leave the characters in the set that appear in the actual text and later remove characters with the Edit text option or change the result with the Format Amount / Date and Time settings in this setup or with Format rules in an Extract action following the Validate action.
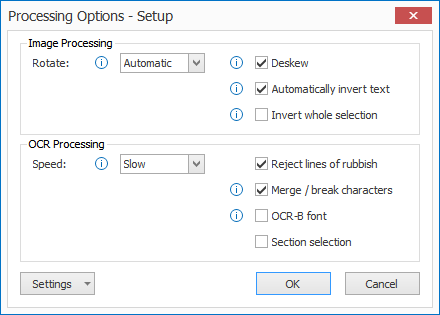
NOTE: these settings do not alter the actual image permanently, they are temporary corrections to correctly extract the text.
There are 2 types of processing options:
01 – Image Processing:
1) Rotate: the selection will be rotated as specified. The rotation occurs just before the OCR extraction takes place. In Automatic mode, the OCR engine will try to detect the orientation of the text automatically. Only use the fixed rotation settings (90° right, 180° and 90° left) if the text on your documents has a fixed orientation that never changes.
2) Deskew: straighten skewed text before OCR processing.
3) Automatically invert text: automatically detects inverted text (white text on a dark background) in the selection and inverts it before OCR processing.
4) Invert whole selection: forces to invert the whole selection before OCR processing.
02 – OCR Processing:
1) Speed: the speed option indicates how exhaustive the OCR process should be looking for improvements. There is a small loss in accuracy if you set it to a faster speed option.
2) Reject lines of rubbish: this detects random characters with a low confidence level caused by noise in the image. Enable this option to automatically delete lines of rubbish.
3) Merge/break characters: enable this option when characters stick together. This technology uses font size detection to determine the breakpoints, so it’s not recommended to use this option on text blocks with a high variety of font sizes on a single line.
4) OCR-B font: only enable it when the text you want to extract is created with the OCR-B font.

Section selection: Experiment with this setting when there are different font sizes on the same line. Sometimes sectioning may drop results when different font sizes occur on the same line.
03 – Text based PDF: text-based PDFs, also known as electronic PDFs, contain computer text. They are typically generated by a text-editor programs like MS Word, Excel or by invoice or report creation software.
By default, we directly extract the original electronic text and don’t need to perform any OCR. This results in to a very fast and accurate extraction of the text.
Apply OCR if PDF contains images: some electronic PDFs contain one or more small images that have logos or small header or footer text. These elements are seen as images, not text. If you want to extract the text in these images, enable this option so it automatically converts the full page to a 300 DPI image. It will then apply OCR to extract the text.
04 – Image based PDF: image-based PDFs, also known as scanned PDFs, are typically generated with a document scanner. They contain an image of each page of that document. By default, we apply OCR to these pages, so the images are converted to text.
Use searchable text layer if present: some scanned PDFs contain an invisible, searchable text layer. If you want to extract this existing searchable text layer instead of applying OCR, enable this option.
If, in a previous Extract action, you have used an Extract Text (Azure Computer Vision) rule with the Convert to searchable PDF option enabled, you are able to use that high-quality text layer when you enable the “Use searchable text layer” option.
This way, you will be able to use the Select text tool on hand-written, arabic, cyrillic or low-quality text:

Enable the “Edit text” option to automatically remove spaces and replace words from the selected text.
The video below shows the Edit text option in action. The alphabetic month is automatically converted to a numeric format:
Press the Setup button to open the Edit text settings.
For example, if you select something like “November 19, 2020” on the document, the replacements will be instantly applied, and the value will become “11/19/2020”.
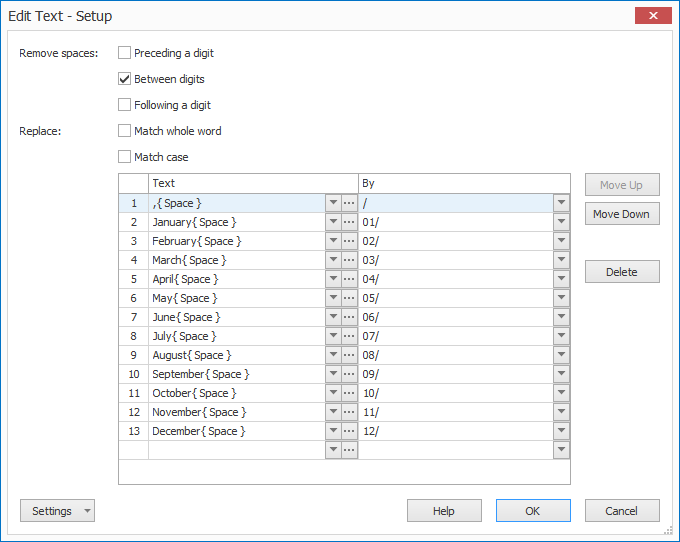
01 – Remove spaces: you can choose to remove spaces preceding, between or following digits. You can also combine these three different options.
02 – Replace: here you set up any replace rules for your extracted text. You can also apply the following options:
1) Match whole word: enable this to only replace text exactly matching the specified word(s). When disabled, it will also replace the specified text if it’s a part of a word.
For example: when disabled and replacing the word “jan” with “01”, words containing “jan” like “january” will be replaced and become “01uary”.
2) Match case: enable this to only replace text that exactly matches the defined word(s)’ case. When disabled, it will replace the specified word(s), regardless the case.
For example: when enabled and replacing the word “JANUARY” with 01, it will only replace “JANUARY” and ignore words like “January”, “january”, etc.
Enter the text you want to replace in the left column. In the right column, you enter the values that the text in the left column will be replaced with.
Press the drop-down arrow to select different system and index values to compose your text.
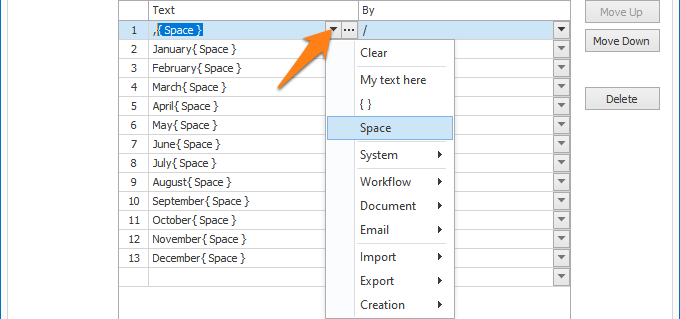
In the example above, we replace the months in long name format followed by a space with their MM/ format. We also replace “,” followed by a space with a “/”. So, a date like “August 15, 1969” would become “08/15/1969”.
You can also specify the location of that text to get a more accurate result. Press the “…” button next to the drop-down arrow to open the setup window for the text location.
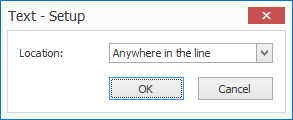
You can select one of the following options:
– Anywhere in the line
– Beginning of line
– End of line
– Beginning of word group
– End of word group
– Beginning of word
– End of word
For example:
Assume you are extracting codes always starting with 1 letter followed by 4 digits like
O-1204
P-5048
W-7042
Etc.
The OCR engine may occasionally make a mistake and read an “O” as a “0” resulting in something like:
0-1204
If you would automatically replace all “0”s with “O”s with the Edit option, you would get “O-12O4” which is not correct either.
However, if you also specify that the element to be replaced (0) needs to be in the beginning of a word. It will only replace the “0” in the beginning of the word and not touch any “0”s in the middle of the word, perfectly correcting the OCR mistake and outputting: O-1204.
To learn more about the difference between lines, word groups and words, please refer to this guide.
You can use the Format option to convert different value types to standardized formats. Press the “…” button to open the setup window.
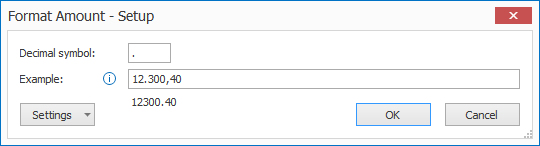
01 – Amount: with the Format Amount option, you can normalize the decimal symbol of amount values, remove thousand separators and currency symbols. This makes the amount format consistent.
02 – Date and Time: with the Format Date and Time option, you can convert date and time values to a standardized format.
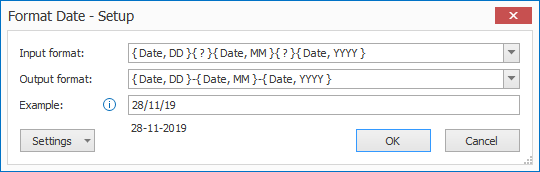
Input format: enter the format that matches the input date and time. You can press the drop-down arrow to select different format types to compose your date and time format.
In this example case, we set up a DD(?)MM(?)YYYY date format. The (?) indicates any character, so if the Date’s separator varies, it will still convert it to the output format.
Output format: here you enter the format for the output date and time. You can press the drop-down arrow to select different format types to compose your date and time format.
In this example case, the date is converted to a DD-MM-YYYY output format.
This feature is to test your Select Text setup and is planned for a future release.
TIP: you can copy the current settings and paste them in another setup window of the same type. Do this by pressing the Settings button in the bottom left of the Setup window and by selecting Copy. Then open another setup window of the same type and select Paste.

