MetaServer > Version History
CaptureBites MetaServer Version History
You can always download the latest version of MetaServer including Operator, Admin clients and sample workflows on the MetaServer Product Page. If you are looking for base installers without any sample workflows, please refer to our download page.
IMPORTANT: Before refreshing or updating your MetaServer, please pause your MetaServer first. You can do this in your Admin Client, under the Server tab. As soon as all your action queues are "yellow" (= paused), you can perform your refresh or update.
This will ensure that no documents in your current queue become corrupted during your refresh or update.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3, it is possible that a Computer ID mismatch can occur.
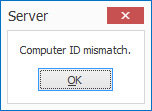
On most systems, the update will not cause any problems. However, occasionally, on some systems this may cause a Computer ID mismatch after upgrading. To fix this issue, please refer to the Computer ID Mismatch troubleshoot page.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1
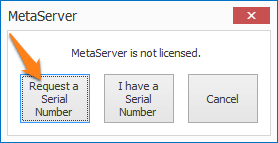
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1, a pop-up window will ask you to request a serial number. If you haven't received a serial number already, please press the "Request a Serial Number" button and fill out the form. We will send you your serial number as soon as possible.
Please also note that old MetaServer activation codes (e.g. "K-123F0-12345-123B4-CD12B-C0D12-E1EB2") are not compatible with this version and future releases of MetaServer. You can apply for a replacement serial number through our online request form.
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23, it is required to republish existing workflows. Select each of your workflows, make a small change, like adding and removing a space to the workflow description, and publish the workflow. If there are documents already imported in the workflow, then you do not have to apply the changes to these documents.
Version 3.0(32) | 2020-03-02
NEW: EXPORT TO DOCUWARE: DOCUMENT LINK: You can now generate a direct link to a document exported to DocuWare. You can then use that link in an email message (for example, to send a notification email), export the value to a database or include it in an index file.
In the Export to DocuWare setup, you simply select a MetaServer field to hold the Document link. To disable this, you just need to select nothing in the fields drop-down list (default).

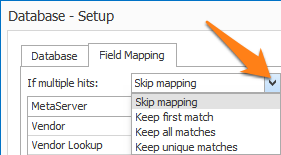
NEW: FIND WORD – DB LOOKUP: MAP MULTIPLE HITS: It is now possible to return multiple hits to mapped fields.
For example, if you first extract an invoice number related to a number of shipments, you can use that invoice number to find all container numbers in a database related to that invoice.
The new options are located in the Field Mapping tab of the “Accept words from database” setup. You’ll find a drop-down with all possible actions to take if the search resulted in multiple hits:
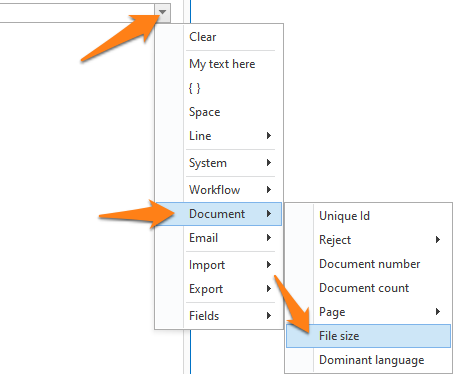
– Skip mapping: the current default behavior and returns “{ Multiple hits }” in the mapped fields.
– Keep first match: returns the first hit. This is useful if your database contains duplicates.
– Keep all matches: generates a list of all matched values in each of the mapped fields, including duplicate values
– Keep unique matches: generates a list of all matched values, removes the duplicates from the combined values of all the mapped fields and populates each mapped field with their values.
Version 3.0(31) | 2020-02-20
ENHANCEMENT: VALIDATION: Input (manual navigation): A Validation field in Input (manual navigation) mode, now auto-focuses and loads the correct page if the data is extracted automatically (i.e. there is a pink rectangle).
Only when there is no value / pink rectangle, it does not do anything and it will stay on the current position in the document. Previously, it did not focus on the extracted value if there was one.
Version 3.0(30) | 2020-01-15
ENHANCEMENT: CONVERT TO FORMAT: The Convert to Black & White setup now features 2 viewers:
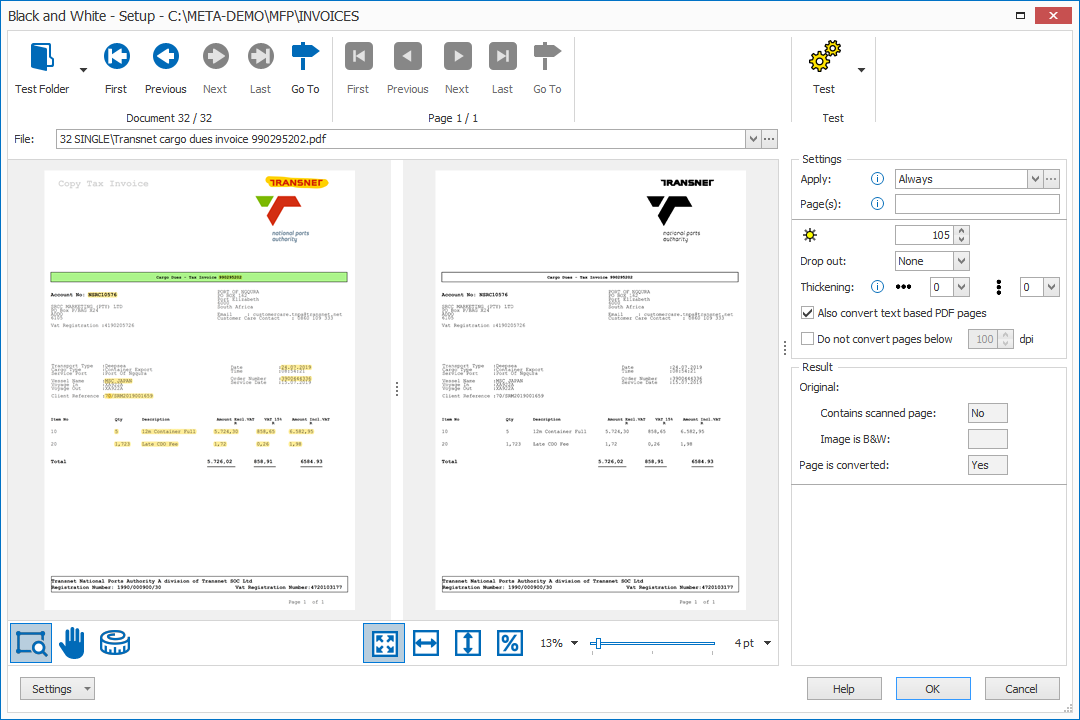
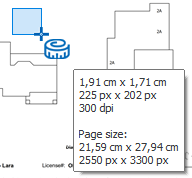
ENHANCEMENT: The Measure Tool is now always available in all viewers. It also shows the total page size in pixel and cm or inch (depending on your region settings).
FIX: { Document Page Number } is a variable that you can use in conjunction with a multi-line field.
For example, if you define a Set Field Value rule and set a field “Line items” equal to:
{ Document Page Number } of { Document Page Count },{ Field, Line items }
Then each line item will be preceded with the page number where it comes from.
The issue was that the line numbers were not updated correctly during Testing of the Extraction rules and always showed as Page 1.
Version 3.0(29) | 2020-01-07
NEW: EXPORT TO SAP – ADVANCED HANDLING OF BARCODE MISMATCHES:
When the barcode on a document does not match the object in SAP, users often generate a new open barcode number in SAP and write that number on the page under the original barcode. The original barcode will be recognized but will fail the barcode check during Export to SAP.
When this happens, the Barcode mismatch condition becomes active and the document can be sent to validation or email export or both.
We updated the sample CB – LATE ARCHIVING workflow to send barcode mismatch documents to a special validation screen where the operator can enter the handwritten number instead of the barcode and resubmit the document to SAP.
NEW: PAGE SIZE VARIABLES TO SEPARATE ON PAGE SIZE:
We added 3 new variables in the Document and System variables category:
{ Document Page Width }: returns the width of a page in cm or inch depending on the windows region.
{ Document Page Height }: returns the height of a page in cm or inch depending on the windows region.
{ Unit of Length }: returns “cm” or “in” depending on the windows region. You can use this to make your separation rules region independent and compare with correct dimensions depending on the detected Unit of Length.
Version 3.0(28) | 2019-12-02
NEW: EXPORT TO DOCUWARE ACTION
With the MetaServer Export to DocuWare action, you can export documents to DocuWare Cloud and On-Premise. Basically, DocuWare stores documents in File Cabinets. Each document can be categorized using multiple index fields. In the Export to DocuWare action, you can directly connect to your DocuWare system and list all available File Cabinets.
After a File Cabinet is selected, the associated index fields are listed and can easily be mapped with MetaServer fields and values. If you use index fields as DocuWare workflow triggers, then you can start a workflow automatically by feeding the trigger index field the correct value directly from MetaServer.
We can also export documents to DocuWare Document Trays. Consider a Document Tray as a generic inbox for documents that need some human interaction like manual review and classification. Document Trays don’t feature index fields because the purpose is to assign them to a File Cabinet in DocuWare manually or by using automation inside DocuWare. You can configure the document name displayed in the Document Tray by using a variety of MetaServer metadata fields and values.
You can apply for a 30 day DocuWare account free of charge here.
Version 3.0(27) | 2019-11-21
NEW: { EMAIL BODY TEXT } VARIABLE: We added a variable { Email Body Text } that contains the flat text of the imported email body. You can set a field equal to { Email Body Text } to extract data from it.
For the moment, you cannot load EML or MSG emails for testing. The easiest way to test extraction from the email body, is to create a special workflow to import emails, convert the body and export the body as PDF. You can then use those body PDFs for testing.
Alternatively, export the { Email Body Text } as a File Index in *.TXT file format, open the .TXT file in Word for Windows, save it as PDF and use those PDFs for Testing.
In the future, we plan to support *.EML and *.MSG files in the test viewer populating the email metadata variables such as the { Email Body Text } based on the selected email MSG or EML file in the Test viewer.
NEW: IMPORT OPTION: ONLY IMPORT FROM SUBFOLDERS: Some customers place PDF files in a sub folder of the MetaServer’s watched folder. The subfolder’s name is actually the batch name and is used to name the final CSV or XML with the metadata of all documents in that subfolder. In these cases, the subfolder is mandatory, otherwise there is no batch name and we cannot name the CSV file. Hence the need to avoid that users put files directly in the root of the watched folder.
If the option is ON, files that are placed directly in the root are ignored.
Version 3.0(26) | 2019-11-14
NEW: IMPORT: SUPPORT FOR PNG: You can now import and process PNG files in the same way as we already did with TIF and JPG files. Refer to the release notes of Version 3.0(25) for more details.
ENHANCEMENT: IMPORT: BETTER SUPPORT FOR SMART PHONE GENERATED JPG AND PNG FILES:
Documents captured with a smart phone in JPG or PNG format often do have incorrect, too large page dimensions causing data extraction and viewing problems.
Enabling this option reduces these very large JPG or PNG files to A4 or Letter Size. Image quality is preserved, only the paper size is updated. JPG and PNG images with small dimensions such as receipts or business cards remain untouched.
You can enable this correction in the Import Email and Import from Folder action. By default, the paper size is Letter Size for US and A4 for other regions. The setting is not only applied during import, but also during testing in Extraction and Separation actions.
Version 3.0(25) | 2019-10-30
NEW: IMPORT FROM FOLDER AND IMPORT EMAIL: MetaServer can now import TIF and JPG from folder and TIF and JPG email attachments.
NEW: IMPORT FROM FOLDER: CREATE A DOCUMENT PER SUBFOLDER: You can now create documents from subfolders in the watched folder containing TIF and JPG files each representing a page of the final document.
A typical input structure would be:
WATCHED FOLDERDOCUMENT001�01.JPG
……………………………………�02.JPG
……………………………………�03.JPG
WATCHED FOLDERDOCUMENT002�01.JPG
……………………………………�02.JPG
……………………………………�03.JPG
……………………………………�04.JPG
The output would be 2 PDFs with the first PDF containing 3 pages and the second PDF containing 4 pages.
In the Export actions you can select following source types:
Imported TIF: These are the original imported TIFs
Imported JPG: These are the original imported JPGs
Imported PDF: These is the PDF derived from the imported TIFs and/or JPGs before any separation or other processing. If the PDF is the result of a subfolder of JPGs or TIFs, then { Import File Name } = the name of the input subfolder.
Processed PDF: The PDF after processing actions such as document separation, searchable PDF conversion, scaling, etc.
Currently we don’t support TIF or JPG yet for testing during setup. So, to test and set up your extraction rules, first convert your JPGs and TIFs to PDF. Once your workflow is configured with PDF samples, you can import and process TIFs and JPGs.
Version 3.0(24) | 2019-10-10
FIX: Documents were time stamped with local time stamps. This could cause issues in the unusual case that an operator or admin client accessed a MetaServer in another time zone. This is now fixed and time stamps are always in UTC format.
FIX: Incorrect handling of “invisible” preprocessing actions (introduced in version 3.0.22) if a workflow had more than one import action and if documents were in the queue at the moment of upgrading to version 3.0.22 or 3.0.23.
Version 3.0(23) | 2019-09-23
ENHANCEMENT: PDFs only containing vectorized representations of text which is not real text but rather a drawing of text objects which is not searchable, are now also converted with OCR. The text in PDFs containing real text (TrueType fonts) is still directly extracted and no OCR is used.
Version 3.0(22) | 2019-09-19
NEW: PASSWORD PROTECTED PDFs: When opening a password protected PDF in Extraction Setup or any other setup, the passwords as defined in the import action(s) of the selected workflow are used to open the PDF. If none of the passwords work, a message opens: “Unable to open password protected file: XYZ.pdf. To use this PDF, enter its password in the Import Action(s) of this workflow.”
NEW: EXPORT TO ALFRESCO: We added a new method to authenticate using Alfresco’s “Basic Authentication” method. This makes the connector work with Alfresco 6.x as well. The new option is called “CMIS 1.1 – Basic Authentication” and can be selected from the Protocol selection list.
ENHANCEMENT: ERROR LOGS: If a file fails to export, the path and name is registered in the Error Logs in C:ProgramDataCaptureBitesProgramsMetaServerDataLog
Version 3.0(21) | 2019-09-11
NEW: ENABLE / DISABLE “SELECT WORKFLOWS” IN THE OPERATOR CLIENT: You control this setting from the Server tab in the Administration client. With this new option, you can make sure that documents of specific workflows are validated on specific workstations.
For example, HR documents can only be validated on PCs in the HR department. You first select the workflows that are accessible by each Operator Client, then you disable the “SELECT WORKFLOWS” option. The “SELECT WORKFLOWS” button will still be available but the selected workflows will be displayed in read only mode and selections cannot be modified in the Operator client.
NEW: IMPORT FROM FOLDER AND EMAIL ACTIONS: PDF Password(s): [ XXX, YYY, ZZZ… ]. If you want to import password protected PDFs, you can now enter all possible passwords in a list.
If none of the passwords work when importing a PDF, the document will be moved to the Errors tab.
Select “Processed PDF” in your export action to export a version of the PDF without password.
Select “Imported PDF” in your export action to export the original version with password.
ENHANCEMENT: OPTIMIZED METHODS FOR PUBLISHING CHANGES TO A WORKFLOW:
– It is never required anymore to restart MetaServer when making changes to workflows, considerably speeding up publishing changes.
– We now show a progress message when publishing changes to existing documents in a workflow if there are more than 50 documents requiring an update.
– We detect the presence of documents per workflow when publishing changes.
Version 3.0(20) | 2019-09-02
FIX: System.Runtime.Serialization.SerializationException error in Separate action when the Find Word with Mask / Words rule uses “Accept words from database” with a MetaServer database
FIX: When exporting a Date / Time to Alfresco, the Date / Time is sent as UTC (was local)
Version 3.0(19) | 2019-09-02
ENHANCEMENT: Log files: date format in the file names is dd-MM-yyyy_… (was MM-dd-yyyy …)
FIX: Convert to Black and White could report “Access denied”
Version 3.0(18) | 2019-08-21
FIX: Convert to Black and White of images at DPI lower than 100: “Value does not fall in the expected range”
Version 3.0(17) | 2019-08-14
NEW: EXPORT TO SHAREPOINT: With the MetaServer Export to SharePoint action, you can export documents to SharePoint on premise or SharePoint Online.
You can construct the folder structure and file name using fixed elements and variables or metadata fields.
Select a library and content type and map variables or metadata fields with its columns.
The export connector makes use of SharePoint’s versioning feature and when a document with the same name is exported a new version of the document will be created.
FIX: If C:META-DEMO did not exist and you opened an Extract action, opened an Extract Text rule and pressed OK, you got an error “System.Exception: Trying to delete a file with a very short path:”.
Version 3.0(16) | 2019-08-12
NEW: EXPORT TO ALFRESCO: With the MetaServer Export to Alfresco action, you can export documents to the Alfresco Community Edition or the Alfresco Content Services Enterprise Edition.
You can construct the folder structure and file name using fixed elements and variables or metadata fields.
Select a custom document type and map variables or metadata fields with its properties.
The export connector makes use of Alfresco’s versioning feature so, when a document with the same name is exported, a new version of the document will be created.
NEW: LOAD BALANCING OPTION: If you watch the same folder(s) with several MetaServers, you need to keep your Import queue low so the documents are evenly imported among all servers. If lots of documents end up in in Validation, all servers become idle. To avoid this, you can now enable the new Load Balancing option in the server tab and set the load balancing limit which does not take documents in validation in consideration. The import limit is an absolute limit including documents in validation.
In summary, the Load Balancing option is all about keeping all servers busy by ignoring documents in validation.
Both limits consider imported documents” before separation”. So a document that is separated in 10 documents only counts as one.
For example:
– Import limit = 20
– Load balancing limit = 5
5 document sets (a document set is a document before separation) are imported and each document set is separated in 10 documents.
8 documents of the set are processed automatically and 2 stay in validation. As soon as all 8 automatically processed documents leave the system and the document set only has documents in validation, that document set is not counted anymore for the load balancing limit.
If all 5 imported document sets only have documents in validation, MetaServer can pull in 5 other document sets because the sets with their documents in validation don’t count anymore.
The total number of document sets in the system will be 5+5 = 10 of which 5 are actively processed and 5 are sitting idle in validation.
If the number of document sets with only documents in validation exceeds 20, the server will pause until documents are validated and some document sets completely disappear from the system.
Version 3.0(15) | 2019-07-25
NEW: TASK SCHEDULER MODULE. This is a new module to run repetitive tasks automatically triggered by one or more timers.
The functionality of the new Tasks feature is fully documented in the MetaServer Online Help.

The Task Scheduler is a separate module in the price list with the following product code:
CB-META-TASK: MetaServer Task Scheduler
Currently there are two main use cases:
1) Syncing a MetaServer database with an external database such as Ms SQL table and cleaning up inconsistent values with replace rules and dedupe records.
2) The automatic deletion of outdated processed document backup files or any other backup files.
TASK SCHEDULER – USE CASE 1:
The first use case is for the automatic synchronization of any type of database table (MS SQL, ODBC, MetaServer) with a MetaServer database. The sync action allows to sync all columns of the source table or only a selection of columns.
In the process, one or more columns of the resulting MetaServer database can be cleaned up, using following cleanup rules:
– Replace: E.g. Replace all “Inc.” and “Incorporated” at the end of all company names. Or replace all periods “.” with nothing in all VAT IDs.
– Remove Spaces: E.g. Remove all spaces between digits in IBAN numbers and TAX IDs.
– Sort by Column rules: E.g. Sort a table by company name.
– Delete Records by Value: E.g. Delete all records where the field type = TEST or Delete all records where the field type = { No Value }
– Delete Duplicate Records: E.g. Only keep records with unique Client IDs.
– When the source database of a MetaServer sync task is not available, the task is skipped until the next scheduled trigger and an email alert is sent if email alerts are enabled for that task.
To check the result of your database sync and cleanup task, you can use the Run Now function and after the task has finished, open your database directly from the Task ribbon. Press the Open Database button to select a database from a list of all MetaServer databases on your system. The button’s drop down shows recently opened databases for quick access.
The MetaServer database will open with the Windows program associated with *.csv files. If there is no associated program defined for *.csv files in Windows, the “How do you want to open this file” Windows dialog will be displayed. Using that dialog, you can associate a default program with the *.csv file type. If you want to change the default program associated with *.csv files, right-click such file in Windows File Explorer and select Open with… / Choose another App / … Select your preferred *.csv Application and select the [ X ] Always use this app to open .csv files.
Version 3.0(14) | 2019-06-22
NEW: CHANGE TO THE QUEUE LIMIT: The Queue Limit defined in the Admin Server tab is renamed to Import Limit. Previously the queue limit was considering documents after separation. Assume that your queue limit was set to 100 and you would import PDFs which were separated in 200 individual PDFs, then this would cause the MetaServer to pause importing until 101 of the separated 200 PDFs would be exported before importing another document.
The new Import Limit which replaces the Queue Limit works differently and checks the number of imported files and disregards any separation action after import.
In our example with an Import Limit of 100, importing a PDF which is separated in 200 PDFs will not pause importing anymore and will continue to import until 100 PDFs are imported. Of course if each of these 100 PDFs would be separated in 200 PDFs, your MetaServer queue would grow to 100 x 200 = 20.000 documents which is too high. So adjust you Import Limit and avoid exceeding 10.000 documents (after separation) at one time in the MetaServer queue. Ideally you never have more than 1000 documents in the queue.
In the client’s status bar and the document counters window, you can see at any moment how many documents are imported and how many are in the queue.
This is an important change implemented for load balancing where multiple MetaServers are watching the same watched folders. The new Import Limit will make sure that all servers will import an equal amount of documents regardless of any separation action.
Version 3.0(13) | 2019-06-19
ENHANCEMENT: Direct SQL Server Lookups and Export to Database: We now also list views in the tables list and you can search in views.
ENHANCEMENT: Workflow ON / OFF button: If the workflow is switched ON, the power icon is now green instead of red. If it the workflows is switched OFF it is red instead gray.
ENHANCEMENT: We added “Copy DB Connection Settings” to copy all DB connection settings (not the lookup and mapping) from one rule to another regardless the type. So the settings can easily be copied between Find Word, Find Word Group, Validation DB Lookup and DB Export. We already did this with SMTP settings and it made sense to do the same with DB settings.
ENHANCEMENT: SELECT SERVER: When the operator presses the menu part of the select servers button, show previously connected servers to do fast switching between MetaServers without having to wait for the discovery.
Version 3.0(12) | 2019-06-13
ENHANCEMENT: ADMIN CLIENT: SERVER TAB: Added 4, 25, 50 and 75 as possible values for the server queue. This in context of watching the same folder with multiple MetaServers.
FIX: VALIDATION: Required option in combination with Check if blank ON or Always check ON made the field non-required if the field was not pre-populated.
– HELP UPDATE:
– Organizer tab
– Validate Action
– Organize Action
Version 3.0(11) | 2019-06-08
ENHANCEMENT: Import from Folder: “Move file to” option: If the file already exists (locked or not locked) in the “Move file to” folder, the moved file generates a new file with a sequence number (x). This avoid errors when the file is locked and will also show if a file with the same name is imported multiple times.
ENHANCEMENT: DB LOOKUP: More efficient handling of multiple DB Lookups.
– During Find Word. If the search field is looking up in an empty Source field, no lookup is done at all.
– During Check Validity: Identical lookups are only performed once.
– When Validation is opened: Field evaluation is not repeated right after Check Validity
Version 3.0(10) | 2019-05-30
This version requires .Net Framework 4.6.2 or higher on both the server and the clients. In case your .Net Framework version is not up to date, you can download the latest .Net Framework from here:
https://dotnet.microsoft.com/download/dotnet-framework
NEW: Find word with Type and Validate: NEW TYPE (Check Digit): Numéro d’identité Luxembourg. You can now extract “Numéro d’identité Luxembourg” using a Find Word with Type rule. We make use of the check digit in the “Numéro d’identité Luxembourg” to locate it. You can also use the same check in a validation rule and only numbers that have a valid check digit and length will be accepted. The “Numéro d’identité Luxembourg” is printed on les “Feuilles d’Impôts” (Tax Declarations) and makes extraction of this number extremely reliable.
NEW: Find word with Type and Validate: NEW TYPE (Check Digit): KBC Bank Mod97 Checksum. You can now extract KBC Customer IDs using a MOD97 check (check digits 00 = 97) using a Find Word with Type rule. We make use of the check digit to locate it. You can also use the same check in a validation rule and only numbers that have a valid check digit and length will be accepted.
NEW: RESERVE FILES DURING IMPORT FOLDERS: This makes it possible to watch the same folder with several MetaServers for load balancing. For example 2 or 3 servers could watch the same folder to convert scanned PDFs to searchable PDF.
Version 3.0(9) | 2019-05-17
NEW: REPLACE “TAB” (Long Space) WITH THE REPLACE TEXT RULE: Sometimes redundant TABs need to be removed from extracted text.
For example if a total amount is printed like this:
1000 . 00
The OCR result may result in this output:
1000→.→00
This makes it impossible to extract the complete amount 1000.00 because it’s spread over different word groups. You can now fix such anomaly by using a Replace Text rule replacing “{ Tab }.{ Tab }” with “.”. This will remove the TABS surrounding the decimal point and leave any other TAB in the text untouched.
NEW: VALIDATION – NEW OPTION TO DISABLE POP-UP BALLOON MESSAGES: If you use the field labels to explain what the user should enter, then you can now disable the pop-up validation error messages (e.g. This field is required. It cannot be left blank.) by disabling the option “[ X ] Show pop-up error messages during validation” in the Validation action.
FIX: ORGANIZER JUMPED TO FIRST PAGE AFTER SEPARATE: When separating documents, the selection always jumped back to the first page of the document set making it hard to look for the next separation point.
Version 3.0(8) | 2019-05-15
FIX: DOCUMENT SEPARATION: If the last page of a document set was a separator to be separated “after the page”, an error occurred.
Version 3.0(7) | 2019-05-07
ENHANCEMENT: SEPARATE DOCUMENT: 2 METHODS ALLOWED: We now allow 2 different separation methods in a single separate document action. For example you can separate on a barcode on the first page and separate on a barcode on the last page.
ENHANCEMENT: ADMIN CLIENT: Remember last selected workflow: We remember the last selected workflow you worked on when re-opening Admin. Before the first workflow was always selected in the Workflows tab when opening the Admin client.
NEW: HELP FILE: Edit – Calculate Time Span
FIX: IMPORT FROM EMAIL: When moving emails to an IMAP folder after processing, they were correctly moved to the defined IMAP folder but only marked for deletion in the inbox. However, they were not purged from the inbox resulting in processed emails both showing up in the processed folder and the inbox. Moved emails are now correctly purged from the inbox.
FIX: ADMIN & OPERATOR CLIENTS: MetaServerValidation.CBMSVSettings and MetaServerAdmin.CBMSVSettings are used to save information relevant to the clients, such as last used workflow, test folders, position of windows etc. When these files were damaged, the corresponding client would not start anymore. This is now fixed and we keep a backup of these files which we restore when the *.CBMSVSettings is damaged. If the backup is also damaged, we load the client with the default settings.
Version 3.0(6) | 2019-05-01
FIX: Import from Folder: Before, when files were placed in the MetaServer watched folder(s), they could not be deleted or renamed anymore. Also opening them in a PDF viewer would make MetaServer fail. This version handles these conditions gracefully.
1) Deleted files are now ignored.
2) Renamed files are imported under the new name.
3) Locked files (for example when a PDF file is opened in a PDF viewer) are skipped until they are unlocked.
ENHANCEMENT: Find Word, Validation DB Lookup, Export to Database and Stored Procedure: MS SQL uniqueidentifier field type is now supported in the mapped fields and stored procedure.
ENHANCEMENT: SELECT SERVER: The Select Server list now also shows the API version. You can only connect with a MetaServer with the same API version as the client. If the API versions don’t match, the MetaServer will be listed but marked in gray.
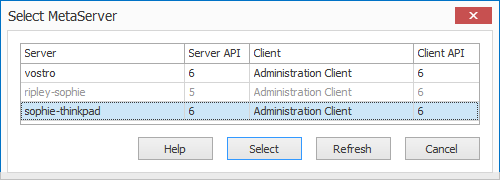
Version 3.0(5) | 2019-03-22
NEW: Multiple Conditions in Set Field Value rule: You can now set up to three conditions combined with “AND” to set the value of a field conditionally. For multiple “OR” conditions, just define several SET FIELD rules like before.
Example 1: set “EMAIL TO” equal to “manager@company.com” if:
TOTAL AMOUNT is greater than or equal to 10000.00
AND
CUSTOMER is equal to NEWCUST
In that case the manager will only be notified for orders >= 10000 that come from customer NEWCUST.
Example 2: Document type detection using keywords. If for example you find keywords that classify a document both as ACKNOWLEDGMENT and OFFER then you can force this combination to for example OFFER with these settings:
Set DOCUMENT TYPE equal to OFFER if:
DOCUMENT TYPE 1 is equal to ACKNOWLEDGMENT
AND
DOCUMENT TYPE 2 is equal to OFFER
Version 3.0(4) | 2019-03-18
NEW: MULTI-SELECT PAGES IN THE ORGANIZER: You can now select multiple pages using the CTRL-CLICK or SHIFT-CLICK technique, or select all pages with the CTRL-A shortcut. Once multiple pages are selected you can apply a function to all selected pages (documents), such as separate, merge, delete and rotate.
FIX: When doing a MetaServer install without any of the sample workflows or demo files, C:META-DEMO was not created. This caused problems when creating an Extract or Separate action pointing to C:META-DEMO as the Test Folder. When MetaServer is now installed, it will create C:META-DEMO automatically if it does not exist.
Version 3.0(3) | 2019-03-13
NEW: UTF-8 BOM and UTF-8 option in Export to Folder: The file index can now be encoded in UTF-8 BOM or in UTF-8 format. Default is UTF-8 BOM. For more info about the byte order mark (BOM), see here:
https://en.wikipedia.org/wiki/Byte_order_mark
NEW: Help button added to Find Number Extract Rule:
https://www.capturebites.com/metaserver/help/extract/120-240/
NEW: OK ALL BUTTON IN VALIDATION: This makes it possible to validate all green fields (valid but forced check) with a single click. The OK All button is optional and is by default disabled in the Operator Client. To enable it, open the Admin client and enable the OK All option in the Server tab.
NEW: The last selected test document folder is now saved as part of the workflow: If you now create an installer and include the last selected test document folder, it is automatically selected as the test folder on the target system. If the target system had a previous version of the workflow with another test folder already selected then the test folder does not change.
ENHANCEMENT: In Validation, the Drop Down List now automatically opens as you type in a database lookup field.
FIX: better handling of changes to test document folders: When previously used test document folders for testing extraction or separation rules for a given workflow were deleted or renamed, the test results were deleted on unexpected moments.
Version 3.0(2) | 2019-03-04
FIX: Find Word with Mask / Words in combination with the Keep All Matches did not work correctly anymore in 3.0.1 and concatenated all words found on the same line of text. Also finding words containing a string did not return the whole word but only the set string.
Version 3.0(1) | 2019-02-18
NEW: EXPORT TO SAP R/3: This connector requires its own activation code. SAP Transport files are placed in C:CaptureBitesMetaServerSAP Transport.
Help is directly accessible from the setup and is located here.
Export to SAP R/3 exceptions are handled as follows:
1) BARCODE EXCEPTIONS: No open internal barcode (late archiving) or already existing external barcode (early archiving). A Document causing such barcode error is moved to the errors tab. However this does not stop the Export to SAP R/3 export action and documents with correct bar codes will continue to be processed. To solve the issue, adjust the barcode value in SAP and retry the documents in the Errors tab. Or delete the documents from the Errors tab and scan them with a correct barcode.
2) THE EXPORT TO SAP R/3 IS NOT LICENSED. Documents exported to non-licensed connector, are moved to the errors tab and the Export to SAP R/3 is halted (red state), documents in the MetaServer queue stay on hold until the problem is resolved. Apply for a license (https://www.capturebites.com/trial). Activate the connector and publish and apply the changes to the current documents in the queue. Documents in the system will be correctly exported.
3) THE EXPORT TO SAP R/3 IS NOT CONFIGURED CORRECTLY. A wrong configuration typically causes an “unable to connect to SAP” error. The document is moved to the errors tab and the Export to SAP R/3 is halted (red state), documents in the MetaServer queue stay on hold until the problem is resolved. Resolve the configuration issue and publish and apply the changes to the current documents in the queue. Documents in the queue and in the Errors Tab will be correctly exported.
4) THE SAP R/3 TRANSPORT IS NOT CONFIGURED CORRECTLY. This will cause an “unable to connect to SAP” error. The document is moved to the errors tab and the Export to SAP R/3 is halted (red state), documents in the system stay on hold until the problem is resolved. You can find more documentation here.
Select the error document and retry the action to rety the export to SAP R/3 action. Documents in the MetaServer queue and Errors Tab will be correctly exported.
NEW: IN WORKFLOWS TAB: DISABLE EMAIL ALERTS – We added an option to disable email alerts. In environments with unknown smtp settings, email alerts can now be disabled until correct SMTP settings are provided. The default for new workflows = Email Alerts OFF (no alerts). When the email alerts are switched off, the Alert icon in the workflows tab is gray. When email alerts are switched on, the icon is red.
Version 3.0(0) | 2019-01-11
NEW: SEPARATE ADMINISTRATION CLIENT – All Admin functions have been removed from the Validation client (now called Operator Client) and moved to an all new MetaServer Administration Client.
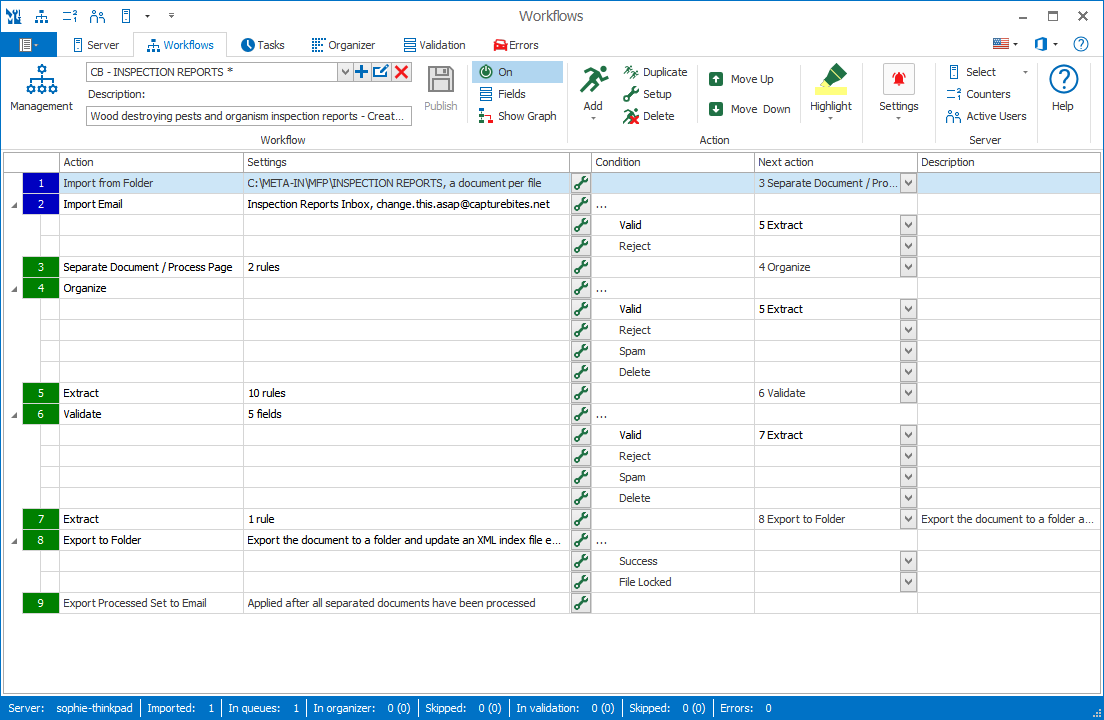
MetaServer Administration Client
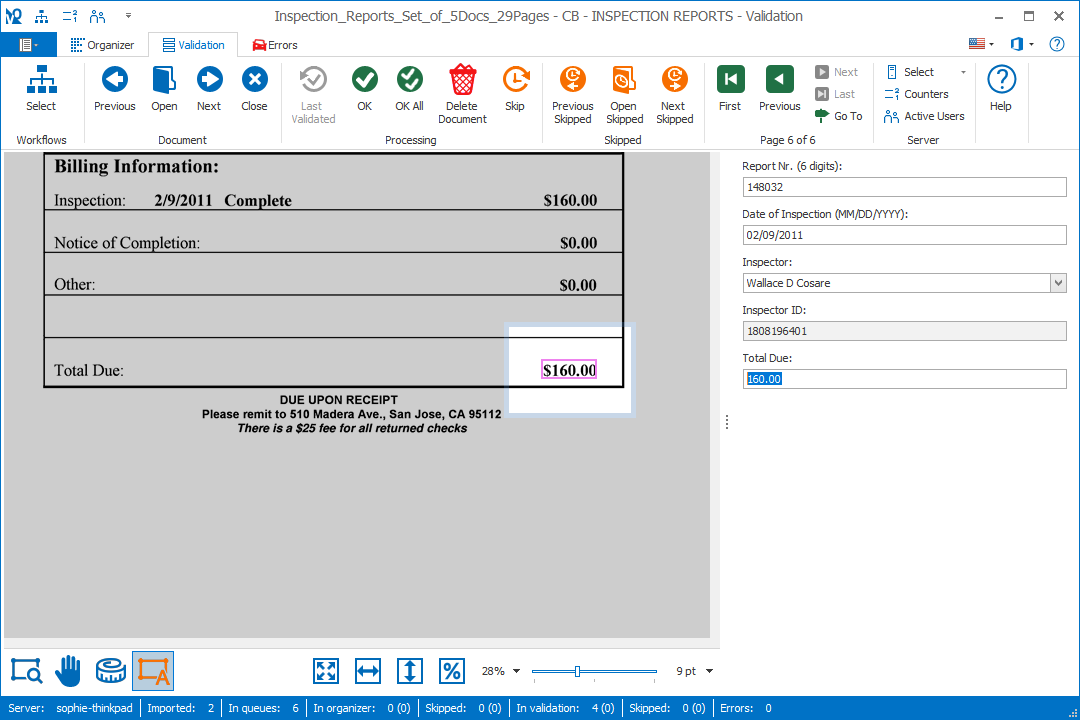
MetaServer Operator Client
NEW: The Validation client is renamed to MetaServer Operator Client. You will now find two icons on the desktop:
MetaServer Admin:

MetaServer Operator:

NEW: All functionality of the Admin and Operator clients are organized in a ribbon UI consisting of 6 tabs in Admin between 1 to 3 tabs (depending on hidden or exposed functionality) in the Operator Client.