MetaServer > Version History
CaptureBites MetaServer Version History
Here you will find all MetaServer release notes, including details of new features, improvements and fixes.
You can always download the latest version of MetaServer including Operator, Admin clients and sample workflows on the MetaServer Product Page. If you are looking for base installers without any sample workflows, please refer to our Downloads page.
If you wish to get notified as soon as a new version of MetaServer is published, please subscribe to our CaptureBites Newsletter.
IMPORTANT: Before refreshing or updating your MetaServer, please pause your MetaServer first. You can do this in your Admin Client, under the Server tab. As soon as all your action queues are "yellow" (= paused), you can perform your refresh or update.
This will ensure that no documents in your current queue become corrupted during your refresh or update.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3, it is possible that a Computer ID mismatch can occur.
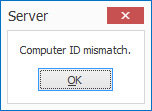
On most systems, the update will not cause any problems. However, occasionally, on some systems this may cause a Computer ID mismatch after upgrading. To fix this issue, please refer to the Computer ID Mismatch troubleshoot page.
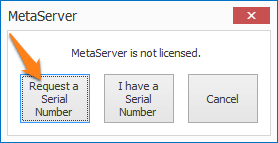
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1, a pop-up window will ask you to request a serial number. If you haven't received a serial number already, please press the "Request a Serial Number" button and fill out the form. We will send you your serial number as soon as possible.
Please also note that old MetaServer activation codes (e.g. "K-123F0-12345-123B4-CD12B-C0D12-E1EB2") are not compatible with this version and future releases of MetaServer. You can apply for a replacement serial number through our online request form.
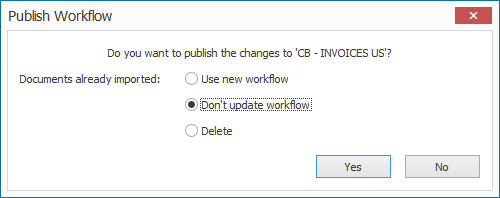
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23, it is required to republish existing workflows. Select each of your workflows, make a small change, like adding and removing a space to the workflow description, and publish the workflow. If there are documents already imported in the workflow, then you do not have to apply the changes to these documents.
Version 3.1(28) | 2024-10-08
NEW #1789: VALIDATE DATABASE FIELD – DB LOOKUP IN CSV TABLES: We now support DB lookup in table cells during validation.
Some Examples:
– Look up internal article numbers and map descriptions for invoice line items
– Look up countries using a DB lookup picklist
– Look up currency codes using a DB lookup picklist
NOTE: For Database fields, there is a limitation for the Cursor options. “In front” and “At the end” options are not supported. The cells are always in “Preselect all” mode.
The setup is like regular DB Lookup fields, but instead of mapping other fields, you map other columns.

FIX #1913: VALIDATE CSV: Duplicating columns generated internal duplicate column ids, causing the following error during validation:
“An item with the same key has already been added.”
The problem occurs when you duplicate column definitions. They generate internal duplicate column ids, resulting in the error.
The fix applies a unique internal ID when you duplicate column definitions.
For an existing workflow with a Validate CSV field in validation that already had duplicate IDs, simply open the setup of the CSV field in the Validate action and press OK. This will fix the ID issue.
If a DB Lookup column was mapped with any of the fixed IDs, then you will see this message after pressing on the Validate CSV field’s setup:

NEW #1874: IMPORT FROM FOLDER – INSTANT IMPORT: A new option has been added called “Instant import”

IMPORTANT: TO BE USED WITH CAUTION. Only use this option with fast, internal drives and only use it with a limited number of workflows.
The option will instantly import files that are placed in the watched folder. By default, when the option is disabled, MetaServer checks the watched folder every 5 seconds. Enabling this option removes this delay.
NEW #1901: TASKS – ERRORS / RETRY ACTION: A new Task rule has been added called Retry Action. You can find it under the “Errors” rule group.
Sometimes a document ends up in the Errors tab for external reasons. With this new rule, you can automatically retry actions with errors containing a specifc string.
For example, an Export to DocuWare action can fail because, at the moment of export, there were too many concurrent DocuWare users logged in to DocuWare.
In that case the document ends up in the Errors tab with the following error:
“Export to DocuWare: Error: NetworkCredential: 403 Forbidden (None of the registered licenses are available for client Administrator). Trace:1 403 Forbidden (None of the registered licenses are available for client Administrator)”
The only way around this error, is retrying the action a few hours later or at night when nobody is connected to DocuWare. It will then resume exporting the document to DocuWare successfully.
With the new Retry Action Task rule, you can perform this step automatically by retrying an action every 6 or 12 hours or so.
For example, with the setup of the Retry Action rule below, all errors containing the string “None of the registered licenses are available for client Administrator” would be retried. Any other errors would stay within the Errors tab.

ENHANCEMENT #1873: REDUCED QUEUE POLLING TIME: We noticed that the queue polling time of 5000 msec (5 seconds) slowed down the throughput speed when single documents were processed. It was not an issue when batches of documents were processed. We reduced the queue polling time to 50 msec for following queues:
– Preprocess Document
– Extract
– Separate Document / Process Page(s)
– Apply Separation & Page Processing
– Check Validity
– Delayed Apply
– Distribute
Ad hoc processing of individual documents is now much faster as well.
ENHANCEMENT#1891: AZURE AI VISION / DOCUMENT INTELLIGENCE: More meaningful error reporting regarding free tier limitations has been added.
1) The free tier will only extract and analyze the content of the first two pages of a multipage document.
2) The free tier can only process files smaller or equal to 4MB
Before, when you processed a file over 4MB, MetaServer returned the cryptic Azure error literally:
“The remote server returned an error: (400) Bad Request.”
We now add an additional description of the potential cause:
“If the pricing of your resource is a free tier (F0), the file may have exceeded the size limitation (4MB) of the free tier.”
When you test a document with more than 2 pages using a free tier subscription, we also now show a warning:
“The free tier limited analysis to the first two pages only”
We only show this te first time when you test the document within the AZVI and AZDI setup. After that, we cache the result. The second time you test the document, the warning does not show anymore.
ENHANCEMENT #1896: LOG FILES: All the “====” and “——” separator lines have been replaced with “******” lines. This displays better when copy / pasted in a GitHub issue.
FIX #1863 #1864: RENAMING OF AZURE COMPUTER VISION AND FORM RECOGNIZER: Microsoft has renamed the two Azure services to the following:
| Old Name | New Name |
| Azure Computer Vision | Azure AI Vision |
| Azure Form Recognizer | Azure AI Document Intelligent |
We have renamed all corresponding MetaServer documentation, settings and info tips accordingly.
NOTE: The Microsoft Azure portal itself still uses the old naming convention for Azure AI Vision. This will probably change over time. In the meantime, MetaServer’s tooltips have already been updated.
FIX #1057: IMPORT EMAIL: The body was attached in the wrong position after publishing any change to a workflow. Even when the body was not selected, it was still prepended after a publish.
FIX #1872: ORGANIZER: Deleting the first page of a document or moving the first page to another document in the Organizer caused all index fields to be cleared. Also, when creating a new document by adding a separator, it cleared document level index fields correctly, but did not preserve set level index fields.
FIX #1884: VALIDATE CSV: When you selected multiple lines of text with the “Select Text Tool” to insert them in a cell, the cell preserved the line separators. This broke the CSV format. We now automatically replace all line separators with spaces.
FIX #1885: VALIDATE DATABASE – FILTER: When a DB field was not required, and the filter value resulted in no values in the drop down, it was impossible to leave the field empty by hitting ENTER.
FIX #1887: VALIDATE DATABASE: The help button in the setup was missing.
FIX #1886: OPERATOR CLIENT – COUNTERS: It was possible to preview a reserved document through the Counters‘ Preview function, even if it was reserved for someone else.
Now, in the Operator Client, reserved documents cannot be previewed anymore. The Admin Client’s behavior has not changed. Any document can still be previewed from there.
FIX #1878: CSV / SQLite DBs: If the SQLite database was empty (0 Kb) or corrupt at startup, MetaServer did not start up correctly and it was impossible to connect a client. We now repair the SQLite database automatically.
FIX #1852: CONVERT TO SEARCHABLE PDF: Using the Convert to Searchable PDF action with Tesseract caused an error on PDF containing and old and a new version of the document.
FIX #1853 #1854: CONVERT TO SEARCHABLE PDF: It’s not possible to convert PDF pages with a width or height greater than 10000 pixels with the Convert to Searchable PDF action with Tesseract. This caused the following error:
“Convert to Searchable PDF: MS_Organize.exe failed on document…”
We now skip these pages.
FIX #1855: CONVERT TO SEARCHABLE PDF: When using the Convert to Searchable PDF with Azure AI Vision, the license of the Extract Text (Azure AI Vision) module was not checked.
FIX #1877: EXPORT TO FOLDER: The variables { Document Number } and { Document Count } were not available for the file name of the File Index and for the content part of the file index setup.
FIX #1867: EXPORT TO DOCUWARE: Starting from DocuWare On Premise version 7.10, it is required to pass the “Organization” name with the login. We added an “Organization” parameter in the Export to DocuWare setup.
FIX #1895: EXPORT TO DOCUWARE: Starting from DocuWare On Premise version 7.11, only the OAuth2 login method will be supported. This required us to upgrade DocuWare.Platform.ServerClient to Version 14. The service connection will perform the OAuth2 authentication in the background, meaning that no further changes to the MetaServer code was required.
For more info, please refer to DocuWare KBA-37505: https://support.docuware.com/en-us/knowledgebase/article/KBA-37505
FIX #1883: EXPORT TO SHAREPOINT: When the maximum length of a text column was exceeded, the reported SharePoint error was too cryptic:
“A text field contains invalid data. Please check the value and try again.”
The new error is more detailed and reports the name of the column causing the problem.
For example:
“Column Order Nr.’, of type ‘Text’: Value exceeds the maximum length: 20: ‘MS_Workflow.Text.Block'”
We now also show the max. length of custom Text columns in the setup. Unfortunately, SharePoint does not report the max. length of system “Text” columns such as “Title”. In that case, we display nothing in the Max. Length column.
FIX #1856: EXPORT TO WORKFLOW: Exporting a separated email to another workflow caused issues.
For example, the first workflow imported emails with multiple attachments. This workflow created separate PDFs for all attachments and for the body. An email with 3 attachments would then generate 4 PDFs.
The multiple PDFs were then exported to another workflow with an Export to Workflow action. The second workflow was used to inspect / correct all documents in the Organizer.
It went wrong in the second workflow after the second attachment went through the Apply Separation & Page Processing action reporting an error:
“Could not find file ‘C:\CaptureBites\MsData\Documents\2024\06.20\16.29.53.893\Created\Files\1.PDF”
FIX #1889: EXPORT TO WEB SERVER: The connector did not support a proxy server. We now set the http request proxy to “DefaultWebProxy” and, similar to the change in Alfresco, we also increased the chunk size to 1Mb (was 64Kb).
FIX #1100: MARK DETECTION: When you created a new Mark Detection rule and started with defining the Scale Anchor, you got the following error:
“Object reference not set to an instance of an object.”
FIX #1870 #1882: ERRATIC ERROR: Some customers experienced the following erratic error:
“Cannot create a file when that file already exists.”
The documented ended up in the Errors tab and a simple “Retry Action” made the document pass successfully. We now implemented an internal automatic retry to avoid the error.
FIX #1902: SERVER TAB – MONITORING: The Monitoring help button was missing.
Version 3.1(27) | 2024-06-06
NEW #1810: ORGANIZE / VALIDATE – CUSTOMIZE REJECT BUTTON: You are now able to further customize the Reject button so operators can also use it for “redirect” purposes (e.g. send to another workflow, save the document in a separate folder, send through email, etc.).
New options include:
1) Set the name of the Reject menu
2) Choose a different icon for the Reject Menu
3) Hide the “OK” & “OK All” buttons in case you want to force the operator to select one of the “Reject” / “Redirect” options instead of pressing “OK”.
You can customize the Reject button in both the Organizer and Validation.


FIX#1794: EXTRACT TEXT (AZURE FORM RECOGNIZER) – ID DOCUMENT MODEL: The segments of the “Machine Readable Zone” did not inherit the pink rectangle / co-ordinats of the complete “Machine Readable Zone”.
FIX #1820: DATABASE LOOKUP – METASERVER DB: New databases did not appear in the database list when opening the list in a DB lookup setup or when accessing the list through the “Open Database” menu button in the Server tab.
FIX #1821: DATABASE LOOKUP – METASERVER DB: The “Open Database” menu button in the Server tab mistakenly opened the SQLite version in the associated CSV viewer instead of the CSV version.
FIX #1816: IMPORT FROM FOLDER – TIF: MetaServer had trouble converting 8 BPP TIF images to PDF reporting the following error and declared the TIF corrupt:
“A graphics object cannot be created from an image that has an indexed pixel format.”
FIX #1814: EXTRACT TEXT (AZURE COMPUTER VISION): The Azure service sometimes failed to retry causing documents ending up in the Errors tab and queues turning red (= critical error). This has been fixed.
FIX #1811: SEPARATE DOCUMENTS / PROCESS PAGE: When you used the Extract Text (Azure Form Recognizer) in the Separate Documents / Process Page action, and when you previewed separation you got an error:
“The process cannot access the file…”
FIX #1815: SEPARATE DOCUMENTS / PROCESS PAGE – DB LOOKUP: Any rule in the Separate Documents / Process Page action that was using a Database Lookup in a MetaServer database caused the following error:
“The MetaServer database manager is not yet instantiated.”
FIX #1809: IMPORT EMAIL: To render an imported email body to HTML to be able to convert it to PDF, we made use of Internet Explorer, which is not supported by Microsoft anymore. We have removed this dependency.
FIX #1812: BOOKLET SPLITTER: When processing PDFs with many pages, an “Insufficient Memory” error occurred when putting them through the Booklet Splitter.
Also, with Fix #1798 in version 3.1(26), we introduced a performance issue when PDFs with many pages were processed with Kofax VRS.
FIX #1818: OPERATOR CLIENT – FRENCH LOCALIZATION: “Last validated” was incorrectly translated as “Dernier organisé”. This has been corrected to “Dernier Validé”.
FIX #1828: CONVERT TO SEARCHABLE PDF: When using the Azure Computer Vision engine and applying parallel page processing, enabling the “Deskew” option caused the following error:
“ProcessImage usage error: inputImageShortName.Length > 128”
This fix was published in version 3.1.27.56.
FIX #1834: IMPORT / EXPORT / FORWARD EMAIL: Updated MetaServer Office 365 Secret. The expired secret affected following actions in MetaServer (error: (401) Unauthorized) :
- Import Email using Office 365 login
- Forward Email using Office 365 login
- Export Email using Office 365 login
- Sending an Email when the processed set is complete using Office 365 login
- Sending Error Emails using Office 365 login
This fix was published in version 3.1.27.56.
FIX #1833: DATABASE LOOKUP: Since our switch to SQLite for MetaServer databases, we had unexpected results when search words included special characters like in “Zdeněk Štybar”, “Gaëlle Duchâtellier” or “Jörg Müller”, etc..
This was related to the uppercase conversion of words with special characters which did not work as expected in SQLite. We implemented an alternate method to do a non-case-sensitive search in a SQLite database for words with special characters.
Words with underscores like in “do_not_reply@capturebites.com” did not work correctly because “_” (underscore) is a reserved symbol in SQLite. We now escape any reserved characters.
This fix was published in version 3.1.27.56.
ENHANCEMENT #1843: CONVERT TO SEARCHABLE PDF: A new option, “Also convert already searchable PDFs” has been added. Before, the Convert to Searchable PDF action always skipped PDFs that were already searchable (Searchable PDF = PDFs with an image + (hidden) text).
Since we can generate Searchable PDFs converted by Azure, users want to replace any (inferior) searchable PDFs to superior Azure searchable PDFs. Hence the new option, “Also convert already searchable PDFs”. This option is enabled by default.
Disable the option if you want to skip processing already searchable PDFs (image + text PDFs). Enable it if you want to improve already searchable PDFs with a superior search layer.
IMPORTANT: Purely text-based, computer-generated PDFs, also known as “electronic PDFs”, are always skipped and never converted to avoid losing the original text.
This fix was published in version 3.1.27.57.
FIX #1791: EXPORT TO DATABASE: When hitting an ODBC Access Database with many updates, sometimes an error occurred:
“ERROR [HY001] [Microsoft][ODBC Microsoft Access Driver] The query cannot be completed…”
This fix was published in version 3.1.27.57.
FIX #1847: DATABASE LOOKUP: SQLite: An error “Index was outside the bounds of the array” occurred randomly. This was related with incorrectly unloading the database.
This fix was published in version 3.1.27.57.
FIX #1845: DATABASE LOOKUP – FILTERS: For Database Lookup, in both Validate and Extract actions, filters did not work correctly when the value had a mixed case like in: “ISTOLA RIPARAZIONI DI MINUZZO STEFANO Ditta Individuale”.
This fix was published in version 3.1.27.57.
FIX #1839: IMPORT FROM FOLDER: The options “Word” and “Excel” were inverted. When you checked “Word”, XLS and XLSX files were imported and vice versa.
This fix was published in version 3.1.27.57.
FIX #1840: IMPORT EMAIL: Emails without a body caused an error:
“ConvertHtmlToPdf: MS_Organize.exe failed on document, error: 2, Unsupported format or corrupted file”
This fix was published in version 3.1.27.57.
FIX #1843: IMPORT EMAIL: Convert Email Body to PDF: The HTML renderer did not convert special characters correctly (as reported by customer in Portugal). We also noticed that embedded and external images were not always rendered correctly. This is also fixed.
This fix was published in version 3.1.27.57.
FIX #1842: VALIDATE: When you opened Validation, the first “Always Check” field was not focused on. Consecutive documents were OK.
This fix was published in version 3.1.27.57.
FIX #1829: DATABASE LOOKUP – METASERVER SQLITE DB: Updating a large CSV caused an update of the SQLite DB while multiple operators were performing lookups in validation. This caused the following error:
“The process cannot access the file ‘C:\CaptureBites\MsData\DB\name-of-large-db.sqlite’ because it is being used by another process.”
This fix was published in version 3.1.27.57.
FIX #1844: SEPARATE / EXTRACT – INTERNAL QUEUE MANAGEMENT: “TOCRDoJob_EG” sometimes could not access document files when temporarily locked by Antivirus software. We now retry up to 4 times, after 15 sec, 30sec, 60 sec, 120 sec, only then error. This avoids errors like:
“MS_Text.exe failed on document…”
We already did such retry for “TOCRWaitForJob”.
This fix was published in version 3.1.27.57.
Version 3.1(26) | 2024-04-09
NEW #1729: NEW VARIABLES: We renamed { Document File Type } to { Imported Document File Type } and created a new variable { Processed PDF Type }.
{ Imported Document File Type } contains the original file type of your imported file.
After import, PDF files remain PDF and any non-PDF formats are converted to PDF. Further processing (like, when using the Digital Imprinter action or Kofax VRS action) can change the PDF type.
In other words, the { Processed PDF Type } value can change as a document goes through different processing steps. The { Imported Document File Type } will always remain the same.
The { Processed PDF Type } can be one of following PDF file types:
- PDF Image
- PDF Image with text
- PDF Text
- PDF Unknown
- PDF Corrupt
The { Imported Document File Type } can be one of following file types:
- Excel
- JPG
- TIF
- PNG
- PDF Unknown
- PDF Image
- PDF Image with text
- PDF Text
- PDF AcroForm
- PDF XFA
- PDF Corrupt
- PDF Password Protected
- TXT
- Word
NEW #1258: IMPORT FROM FOLDER / IMPORT EMAIL – TXT and RTF File support: We now also support the import of TXT (TXT,CSV) formats and RTF format files.
To import and convert TXT and RTF files, you require MetaServer’s “Import Office Documents” module. Without this module, the import action will show an error in the Server tab indicating that the file cannot be imported because “Module ImportOfficeDocuments is not licensed”.
NEW #1773: EXTRACT TEXT (AZURE FORM RECOGNIZER): We have added support for preview model “2024-02-29 (Preview)”.
For more info, please visit:
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/whats-new?view=doc-intel-4.0.0&viewFallbackFrom=form-recog-3.0.0&tabs=csharp#february-2024
NOTE: Public preview version “2024-02-29-(Preview)” is currently only available in the following Azure regions:
- East US
- West US2
- West Europe
In this preview version, the AI quality of reading order and logical roles detection has improved.
ENHANCEMENT#1661: DATABASE LOOKUP – IMPROVED CSV HANDLING: Since the initial versions of MetaServer, we have been supporting database lookup in csv files. This has been very popular because of its simplicity. You just drop a CSV file in the MetaServer DB data folder (C:\CaptureBites\MsData\DB) and it becomes available in MetaServer as a MetaServer database that you can use to perform lookups during Extract or Validation.
Updating the database is as simple as copying a new version of the CSV in the DB data folder. MetaServer detects the change and instantly make the new version available.
The CSV concept allows you to access a couple of million records, but at a heavy memory cost, sometimes causing “Out of Memory” issues. To address this issue, and make it possible to look up in CSV databases up to a few million records, we implemented an automatic conversion to a SQLite database. This has the advantage that the CSV data does not have to be loaded in memory anymore, resolving the memory issues, and without affecting performance.
Most importantly, the mechanism to create or update a new MetaServer database remains identical to before.
The SQLite database is a file that lives next to the CSV files in the DB data folder. For example, if you copy “zipcodes.csv”, then the SQLite version is auto-generated and after a few seconds “zipcodes.sqlite” will appear as well.
When you first install MetaServer version 3.1.26, it will generate all SQLite versions of all your CSV files at startup. This process only takes a few seconds.
We recommend to only edit the CSV files in case of updates and avoid opening or editing the SQLite file to avoid locking or sync issues. The CSV file is still the master database and you change the SQLite database through the CSV file. This guarantees absolute compatibility with existing MetaServer workflows.
ENHANCEMENT #1788: IMPORT EMAIL – OFFICE 365: We renamed the “Mailbox” parameter to “Linked account” to avoid confusion. We also adjusted the info tip accordingly.
ENHANCEMENT #1744: WORKFLOWS – REDUCED FILE SIZE: Workflows that include many validation rules had a larger file size. The workflow file size is now compacted, only taking up 50% of the file size compared to before.
ENHANCEMENT #1748: TASKS – SYNC METASERVER DATABASE: When syncing a MetaServer DB with a DocuWare cabinet, for usability reasons, we renamed some of the parameters to be consistent with correct DocuWare terminology:
Url => Address
Table => Cabinet
ENHANCEMENT #1446: UPDATED BARCODE SDK: We upgraded the barcode SDK to version 9.3.1.11 (was 9.1.1.5). These are the improvements:
- Memory Issue fixed
- Better reading of QR codes with part of an edge missing
- Improvement to the QR Code algorithm in both speed and read rate
- QR-Code recognition improved where the finder patterns are damaged
- 5% faster than previous versions
- Code 128 recognition has been improved where there are unusual relative widths between bars and spaces
ENHANCEMENT #1758: EXPORT TO DOCUWARE: In the Export to DocuWare action, we now show the data types of the DocuWare fields in the mapping list.
ENHANCEMENT #1752: VALIDATE: DB LOOKUP – BLACK LIST: You can select a field to specify a list of blacklisted values. We also made the following changes:
- The info tip has been changed to: “You can select a field here to specify a list of blacklisted values. Separate values by a ;”
- The validation field itself can’t be selected as a black list field anymore.
ENHANCEMENT #1780: SERVER TAB – QUEUES: We added the “Import from Web Service” action queue to the action queue list.
NOTE: Uploading documents to MetaServer through REST API and thin client validation is still in development and is only available on request.
ENHANCEMENT #1799: ERROR LOGS: We now also log the MetaServer data drive letter, its capacity and free space:

FIX #1757: EXPORT TO DOCUWARE: We incorrectly set the DATETIME format for DATE fields causing issues when exporting dates to DocuWare Trays. This caused loss of date information when moving the documents from a Tray to a Cabinet.
FIX #1783: TASKS – BACKUP METASERVER DATABASE: The Backup MetaServer Database rule did not overwrite the file if it already existed in the target backup folder.
FIX #1753: EXTRACT- FORMAT CSV: If “;” (semicolon) was specified as the CSV delimiter, it was not used in Excel Hyperlink Formulas.
FIX #1754: VALIDATE – CSV: The Validate CSV rule inherited Windows’ regional settings to set the CSV delimiter, which caused unexpected results. You can now specify the delimiter (“,” (comma) or “;” (semicolon)), independent from your Windows’ regional settings.
FIX #1779: VALIDATE – DB LOOKUP: When the “Search as you type” option was disabled, and you changed lookup values by typing or pasting another lookup value, the lookup sometimes did not update mapped fields.
FIX #1786: VALIDATE – CSV: When the “Line Items” field was equal to “”,””,””,””,””,””,”” (= one empty row), the “Check Validity” action queue caused an error: “Index was out of range.”
FIX #1755: VALIDATE – CSV: For the Validate CSV rule, when a CSV field was formatted as an Excel Text field (prefixed with “=”), and you edited that field during validation, the “=” prefix was lost.
We also noticed that Excel has problems parsing the CSV correctly when a field prefixed with “=” contains a delimiter like “,” (comma) or “;” (semicolon). We now suppress the “=” prefix when the field contains these delimiters.

FIX #1756: SEPARATE DOCUMENT / PROCESS PAGE: The Extract Text (Azure Form Recognizer) rule was not available in the Separate Document / Process Page action.
FIX #1785: SEPARATE DOCUMENT / PROCESS PAGE – SETUP & PREVIEW: When you interrupted the Separate Document / Process Page Preview by pressing “Cancel”, the following error occurred:
“Object reference not set to an instance of an object.”
FIX #1807: SEPARATE DOCUMENT / PROCESS PAGE: When you would separate large sets (+100 pages) and the set had pre-extracted fields with lots of metadata or some fields were populated with a lot of data during separation, then the Separate Document / Process Page action showed a long delay on the last page before moving on to the next step.
Also, the “Preview” function in the Separate Document / Process Page action setup showed a similar delay on the last page.
FIX #1767: IMPORT EMAIL: A very unusual case, but we have seen email attachments being named with illegal file name characters such as ” : < > * etc.
The concrete example we were informed about, was a transport company sending invoices with names like “INVOICE=> ORDER002867073.PDF”, which contained the illegal “>” character.
These emails were probably produced by an automated system. Because of the illegal characters, MetaServer was not able to save these attachments with the original file name. We now automatically replace any illegal file name characters in the attachment file name with “_” (underscore).
FIX #1766: IMPORT EMAIL – GMAIL: When the MetaServer service starts, Gmail import accounts were sometimes giving the error:
“The remote name could not be resolved: ‘oauth2.googleapis.com'”
FIX #1797: IMPORT EMAIL: For the Import Email action, in the unusual event that the HTML version of the body cannot be converted to PDF, we time-out the HTML to PDF conversion after 5 minutes and then convert the Text version of the body to PDF.
FIX #1791: LOG: For improved debugging, we have added additional info related to the following error:
“ERROR [HY001] [Microsoft][ODBC Microsoft Access Driver]. The query cannot be completed. Either the size of the query result is larger than the maximum size of a database (2 GB), or there is not enough temporary storage space on the disk to store the query result.”
FIX #1759: SERVER TAB – ACTIVE QUEUES ONLY MODE: Searchable PDF queues were not listed on page refresh, but only on document refresh.
FIX #1760: SERVER TAB – ACTIVE QUEUES ONLY MODE: Wrong queues were marked bold.
FIX #1795: TASKS – SYNC METASERVER DATABASE: Date fields were synced as DATETIME fields with trailing 00:00:00 times.
FIX #1796: TASKS – SYNC METASERVER DATABASE: We now only list “Cabinets” and hide “Trays” in the Cabinet dropdown. Listing trays did not make sense and was confusing when the tray had the same name as the linked cabinet.
FIX #1793: SUA REMINDER: The SUA warning only occured when the main MetaServer was NOT set to “PRP”. It needed to only warn when the main MetaServer was set to “PRP”.
FIX #1798: KOFAX VRS: In some cases, the Kofax VRS action caused following errors in MetaServer version 3.1.25:
“Error: Index was outside the bounds of the array.”
“Error: The given path’s format is not supported.”
This fix has also improved the overall Kofax VRS performance.
If you have experienced these errors, please update MetaServer to version 3.1.26 or higher.
Version 3.1(25) | 2024-02-19
NEW #1661: EXTRACT TEXT (AZURE FORM RECOGNIZER) – “ID DOCUMENT” MODEL: in the Extract Text (Azure Form Recognizer) action, we now also support the ID Document prebuilt model.
More detailed information can be found here:
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-id-document?view=doc-intel-3.1.0#supported-document-types
Unlike the other prebuilt models, the “ID Document” model can also classify the document, which value is returned in the field “docType”. We expose this value in the mapping as “Document Type” and can contain one of the following values:
- driverLicense
- passport
- nationalIdentityCard
- residencePermit
- usSocialSecurityCard
On passports, the model also detects the “Machine Readable Zone”.
For example:
P<BELMOONS << JEAN<DOMINIQUE<MARIE<LOUISE<R <<< EN130290<4BEL6211198M2303130 <<<<<<<<<<<<<< 02
This Machine Readable Zone is also decomposed in subelements that we expose as follows:
| Value Name | Example Value |
| Machine Readable Zone Country Region | BEL |
| Machine Readable Zone Date Of Birth | 1962-11-19 |
| Machine Readable Zone Date Of Expiration | 2023-03-13 |
| Machine Readable Zone Document Number | EN130290 |
| Machine Readable Zone First Name | JEAN DOMINIQUE MARIE LOUISE R |
| Machine Readable Zone Last Name | MOONS |
| Machine Readable Zone Nationality | BEL |
| Machine Readable Zone Sex | M |
NEW #1715: EXTRACT TEXT (AZURE FORM RECOGNIZER) – “DOCUMENT CONTENT PRINTED AND HANDWRITTEN” VALUE: in the Extract Text (Azure Form Recognizer) action, we have added a new value to all prebuilt models called “Document Content Printed and Handwritten”.
There are now 4 different “Document Content” values:
- Document Content
- Document Content Printed
- Document Content Handwritten
- Document Content Printed and Handwritten
If you select “Document Content”, it will return all Printed, Handwritten and Barcoded values.
If you just want to return barcode values, use the already existing “Barcodes All”. You can also select a specific barcody type, like “Barcodes QRCode”.
NEW #1716: EXTRACT TEXT (AZURE FORM RECOGNIZER) – API VERSION “2023-10-31-preview” EXPOSED: in the Extract Text (Azure Form Recognizer) action, we now expose the public preview API version “2023-10-31-preview”. We still default to the “2023-07-31 (GA) General Available” API version but you can easily switch to “2023-10-31-preview” to check for possible improvements on your documents.
More detailed information about the “2023-10-31-preview” API version can be found here:
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/whats-new?view=doc-intel-4.0.0&tabs=csharp#november-2023
IMPORTANT: The “2023-10-31-preview” API version is only available for resources defined in following locations:
– East US
– West US2
– West Europe
NEW #1732: LICENSE – WARNING WHEN MAINTENANCE EXPIRES: for both the Admin and Operator clients, a warning will be shown 3 months before the MetaServer licenses’ maintenance expiration date. The contact info depends on our license manager system.
When the expiration date is in the future:

When the expiration date is in the past:

NEW #1511: EXTRACT – FIND WITH REGULAR EXPRESSION: for advanced users, we implemented a new Find with Regular Expression rule.
In this rule, you define the target and source fields and, optionally, some test text. As you create your Regular Expression (= RegEx), it is instantly applied on the test text and you can see the result below it:

If you are interested in learning RegEx, we recommend this site:
https://regexr.com/
NEW #1207: ORGANIZER / VALIDATE: OPEN DOCUMENT – PREVIEW: you can now preview a document directly from the Organize / Validate tab’s Open Document window. Before, you had to open a document in the Organize or Validate tab to view it. If you returned to the Open Document list, the list needed to be completely reloaded. Now, you can preview the document without closing the document list.
IMPORTANT: Reserved documents can not be previewed by the Operator client. They can be previewed with the Admin client.


NEW #1080: WORKFLOWS: RECENT WORKFLOWS LIST: in the Workflows tab, we now pin the 10 most recently published workflows on top of the workflows selection list. The 10 most recent workflows are separated from the other workflows with a horizontal line:

The top 10 workflows are sorted by their last published date and time. This means that the workflow that you are working on is always first in the list. The less frequently used workflows are listed alphabetically under the 10 most recent.
NEW #1135: SERVER: SHOW ACTIVE QUEUES ONLY: in the Server tab, when enabling the “Active Queues Only” option, you are only shown the queues that have been active in the last 6 hours. Starting from this version, this option is enabled by default. If you want to see all 186 queues, you can just disable the option.
Queues that are always shown are:
– All red queues (= queues in error state)
– All orange queues (= queues in auto-recover state)
– Monitoring
– Refresh Tokens
– Task
– Unlock Unresponsive Sessions

NEW #1217: DOCUMENT COUNTERS – DETAILS & HISTORY: a “Details” button has been added to the Document Counters window. Previously, we only displayed the number of documents in each queue in the Document Counters window. This made it impossible to know which documents were in a given queue.
With the “Details” button, you can now select a queue, like “Extract”, and open the list of documents in that queue. This list shows more details about each document in the queue.

In the Details window, you also have a “History” button that shows you the selected document’s previous, completed actions. When a document is actively being worked on in a queue, it is locked and will be listed in italic text style.

With the “Preview” button, you can view the document as a PDF.
NOTE: locked documents can not be previewed.

NEW #1708: EXPORT TO ALFRESCO – CHECK OUT OPTION: in the Export to Alfresco action, an option has been added to enable the Alfresco “Check out” feature. If enabled and when MetaServer creates a document, MetaServer also immediately checks out the document. This means that no other process can touch it as long as MetaServer is creating the document. Once the document is complete and the PDF is fully uploaded, MetaServer checks the document in again.
NEW #1690: TASKS – TASK EVERY X MINUTES: in the Trigger Task action, we have added a new Trigger type, “Trigger a task every x minutes”. The default is set to 60 minutes.
NEW #1690: TASKS: SYNC METASERVER DATABASE – DOCUWARE CABINET: in the Sync MetaServer Database Task action, you can now select a DocuWare cabinet as a data source to sync its metadata with a MetaServer CSV database.
NEW #1690: RUN – RUN TASK: with the new Run Task action, you can run a task if a document is processed. For example, if a subscription is processed creating a document in DocuWare with all account info as metadata, then, after exporting the document to the Subscription cabinet, you can run a task to sync the metadata of the subscription cabinet with a MetaServer database.

ENHANCEMENT #1691: AZURE COMPUTER VISION / FORM RECOGNIZER: when internet is down, the Azure recognition queues do not turn red anymore (critical error) but instead turn orange and report “No Internet Available”. As soon as the internet connection is up again, the Azure extraction queues resume working.
For the Convert to Searchable PDF and Extract Text (Azure Computer Vision) action, MetaServer will save partial results on disk so that they don’t have to be created again when the Internet is available again.
ENHANCEMENT #1603: EXTRACT (AZURE FORM RECOGNIZER) – “OTHER FORM” MODEL: “Selection Mark” form fields are now pre-fixed with the words “Selection Mark” to distinguish them from other form field types.
ENHANCEMENT #1707: ORGANIZER / VALIDATION – LAST ORGANIZED / LAST VALIDATED: during validation, you can go back to the last validated document for a specified time. After this delay, document processing resumes automatically, and the document won’t be available anymore for validation or organize. However, before, all validated or organized documents were halted for the specified delay, even if the documents were not the last validated or last organized anymore.
This is now improved. As soon as a new last validated or last organized document becomes available, previously validated or organized documents are instantly pushed to the next step, regardless of whether the delay is elapsed or not.
ENHANCEMENT #1510: WORKFLOWS: when you add an action between two actions, it changes the connections of the previous action, potentially messing up the workflow. We have improved this. When you now add an action between two actions with connections, it creates an orphaned action, leaving the original connections intact. The user will then need to connect the new action correctly.
ENHANCEMENT #1698: WORKFLOWS & TASKS: we have removed the “Internet Timeout” setting. This was an unused legacy setting that caused confusion. It was used in older versions of MetaServer and was related to HTML to PDF conversion and Email to PDF conversion with the old EVO SDK.
ENHANCEMENT #1709, #1711, #1718, #1719, #1720, #1721: RETRY LOGIC: we have made enhancements related to retrying certain actions in case of erratic anti-virus related errors and logging:
- Avoid empty exception files: Exception is written in one single call, with retries
- Extract Barcode: Couldn’t find file: Added retry
- Extract Text: Cannot access the file: Added retry
- Task: Sync Database: If a connection times out, Added retry
- Archive Email: Connected host has failed to reply: Added retry
- Archive Email: Connection forcibly closed by remote host: Added retry
- Import Email: Connection forcibly closed by remote host: Added retry
- Import Email: The server has closed the connection: Added retry
- DeserializeDocuments.RestoreSet: Could not find a part of the path: If import email fails after the document is partially created, the document folder is deleted
- The generic “Unable to close document” is now “Unable to xxx document: …” where xxx is “open”, “unload”, “get”, “get header of ” or “close”.
- If an email cannot be imported because of a corrupt header, we now log all info to make it possible to find the original email back in its inbox.
Example of logged email data :
Workflow: GITHUB-1279 – CORRUPT EMAIL ATTACHMENT
Source: Office 365
Watched folder: Inbox
Document: 2024/01/19 17:36:31.313
Id: AS1P251MB0606EA9E77D2FB545C4DFCEBEB702@AS1P251MB0606.EURP251.PROD.OUTLOOK.COM
Date: Friday 19 January 2024 11:44
From: invoicing@orange.be
To: info@capturebites.com
Subject: Invoice ** Possible Spam **CMR 0012984300
ENHANCEMENT #1439: IMPORT – EMAIL WARNING: in case of an import fail because of Email or Watched Folder access issues, we now show the server’s name in the subject as well.
For example: “MetaServer: XPS13: Watched folder is not reachable”
ENHANCEMENT #1699: SERVER TAB – QUEUES: we have removed legacy queues which were not used anymore in the later version of MetaServer:
- Classify
- Convert Email Body to PDF
- Convert HTML to PDF
- Download URL
- Select
ENHANCEMENT #1574: EXTRACT – REPLACE TEXT: If any other option besides “Anywhere in the line” is selected for a given replace entry, the entry is marked in green. The green color coding helps identifying replace entries with special settings.
ENHANCEMENT #1743: ORGANIZE / VALIDATE – IMPROVED REJECT & DELETE DOCUMENT: before, it was impossible to go back to a document with the Last Organized or Last Validated function after rejecting or deleting it. This is now possible.
Also, previously, the reject button was a split menu/button, where the last selected reject reason was the button part. Sometimes, operators accidentally pressed the button part of the Reject function to try to open the list of reject reasons causing the selection of the wrong reject reason. To avoid this, we changed the Reject button and made it a menu control and not a split button anymore.
The name of the menu control is always “Reject” and when clicked, it opens a menu listing the different reject reasons. The user then selects the correct reject reason. This simplified and consistent behavior should avoid any confusion or mis-clicks.
IMPORTANT: in order to have these enhancements applied on workflows that were published before MetaServer version 3.1.25, you need to republish these workflows.

ENHANCEMENT #1714: EXTRACT (AZURE FORM RECOGNIZER): we now report the barcode type in the test result box when “Show info” is enabled.

FIX#1693: EXTRACT TEXT (AZURE FORM RECOGNIZER): if you mapped the “Dominant Language” value and the document had no text, an error occurred: “The given key was not present in the dictionary.”
FIX #1027: ACTIVATING & SAVING WORKFLOWS: previously, you could not activate a workflow and also save any changes made so far if there were not enough licensed workflows left. Now, the changes will be saved but the workflow will remain inactive in order to respect the number of licensed workflows.
Example of a warning message: “The workflow has been disabled. You have requested 35 workflows to be activated but you are only licensed for 34.”
FIX #1509: MOVING ACTIONS: previously, when you duplicated an action and you moved it, the wrong action was marked red.
FIX #1710: IMPORT PREPROCESSING – UPDATED PDF TOOLKIT VERSION: when importing documents, we perform some pre-processing to detect the number of pages, the pdf type, if required, use a password to read the PDF etc. On some bookmarked PDFs, our PDF toolkit failed. We upgraded the DevExpress toolkit from version 22.2.6 to version 23.2.4. These bookmarked PDFs are now correctly processed.
FIX #1712: IMPORT EMAIL – UPDATED EMAIL TOOLKIT VERSION: some emails did not import and returned an error “Invalid character at position 38 in header ‘Date'”. We upgraded our email libraries from Rebex version 5.0.7620 to Rebex version 7.0.8755, so these emails can now also be imported.
FIX #1697: IMPORT EMAIL – GMAIL: when the internet connection is temporarily offline, any Import Email action turns orange and will try to reconnect automatically. Once internet is online again, Import Email actions automatically turn green and resume importing. There was an issue with Gmail accounts when internet was dropped. The Import Email queue became orange, but, after 1 minute, it became red because Gmail failed to reconnect. This is now fixed.
FIX #1724: IMPORT EMAIL – OFFICE 365: if MetaServer restarted, reconnecting to an Office365 account sometimes caused an error: “The remote name could not be resolved: ‘login.microsoftonline.com’.
FIX #1727: IMPORT EMAIL – ILLEGAL CHARACTERS IN ATTACHMENT FILE NAME: an error occurred and the Import Email queue turned red when the attachment file name contained a pipe character (“|”).
- The error is now added to the list of errors to retry
- It logs the action label instead of the generic “OfficeConnector”: “ImportEmailAction”, “RefreshTokensAction”, “EmailAlertAction”…
- In the Server tab: the “Last time applied” column is now updated for “Monitoring”, “Refresh Tokens” and “Unlock…”.
FIX #1723: VALIDATE – DB LOOKUP: if you had a document open in the Operator Client and the MetaServer service was restarted through the Admin Client, the connection to the MetaServer database was lost and, as soon as a database lookup happened, an error occured.
FIX #1730: KOFAX VRS – TESTING FAILED ON E-PDF: in the Kofax VRS action, testing failed on electronic PDFs while it should just ignore them. Run time worked correctly.
FIX #1435: VALIDATE – FONT-SIZE IN NOTE FIELD: the “Always check” option did not work if the Font size was set to “Medium” or “Large”. The font size was also still displayed in “Small” size until you clicked in the Validate Note Field.
FIX #1745: ORGANIZE: before, if you deleted all pages of a set in the Organizer, it was possible to OK this zero page set. The set then got stuck in the Processed queue. We now make the OK button inactive on zero page sets and it is only possible to delete them.
FIX #????: DELAYED APPLY: Correction to make sure the “Delayed Apply” time stamps are unique and to avoid the error:
Delayed Apply: An entry with the same key already exists.
This was blocking the “Delayed Apply” queue. This fix was added on 05-MAR-2024.
Version 3.1(24) | 2023-11-16
NEW #1578: EXTRACT TEXT (AZURE FORM RECOGNIZER): Support for latest API version “GA 2023-07-3”.
This API version includes:
– Further improvement on the invoice header and line item extraction
– The “Invoice” model supports many more languages and currency codes. More detailed information can be found here:
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-invoice?view=doc-intel-3.1.0#supported-languages-and-locales
– Returns the dominant language of a document in all models
– Reads all 1D and 2D barcodes on a document in all models
– Reads CMC7 font in the Read model
The old API version is not supported anymore. Existing workflows with the Extract (Azure Form Recognizer) rule using the old API version will automatically switch to the new version.
More details are explained in the “READ” MODEL version history note below (#1430).
NEW #1430: EXTRACT (AZURE FORM RECOGNIZER) – “READ” MODEL: We now support the “Read” model in the Extract (Azure Form Recognizer) module.
The “Read” model in the Azure Form Recognizer engine is more advanced than the Azure Computer Vision engine. It’s only slightly more expensive ($1.5 / 1000 pages vs $1 / 1000 pages).
More detailed pricing can be found here: https://azure.microsoft.com/en-us/pricing/details/ai-document-intelligence
Additional capabilities of the Extract (Azure Form Recognizer) “Read” model as compared to Azure Computer Vision:
1) Reads barcodes with following types:
Codabar
Code128
Code39
Code93
Datamatrix
EAN13
EAN8
Interleaved 2 of 5
UPC-A
UPC-E
PDF417
QR Code
You simply map the barcode type(s) you are interested in with MetaServer fields. If the model returns several bar code values, you can use standard MetaServer rules like “Find Word with Mask” or” Find Selected Text” to zero in the value you are interested in.
2) Returns the dominant language. Just map “Dominant Language” with a MetaServer field to get the iso code of the dominant language.
You can find a list of language codes that can be detected by the model here:
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-read?view=doc-intel-3.1.0#detected-languages-read-api
3) Reads CMC7 font typically found on French and Spanish checks
4) Better reading of individual characters like, for example, a page number in a corner without any text around it.
5) Improved segmentation distinguishing machine printed from handwritten text:
[Document Content Printed] returns all machine printed text.
[Document Content Handwritten] returns all handwritten text
[Document Content] returns all text.
NEW #1586: EXTRACT TEXT (AZURE FORM RECOGNIZER) – “OTHER FORM” MODEL: Azure’s “Other Form” model automatically detects key value pairs for fields, tables and check boxes on any form type. You just load one sample of your form, the “Master Form”, to detect the data elements on the form which can then be mapped with MetaServer fields. This reduces the time to configure the extraction of a form considerably.
You can find more detailed information about the “Other Form” model setup on the Extract Text (Azure Form Recognizer) rule’s online help page.

NEW #1537: EXTRACT – FORMAT CSV: with MetaServer’s Format CSV rule, you can merge and convert fields with header data and / or multi-line values in a compatible CSV format. This rule is essential if you’re planning to validate a table using the Validate CSV rule or when you’re exporting a CSV file index.
Some automatic CSV formatting includes:
- Values are put between double quotes in order to handle commas (,) and semicolons (;) inside values correctly.
- Double quotes (“) inside the values are doubled. This is critical to preserve the inch symbol in a value like, for example, 65” TV.
- Tabs are replaced by spaces.
- Any conflicts where columns do not have the same number of lines as other columns are automatically resolved.
- If one of the merged fields only contains one value (like header data), that value is repeated as many times as there are rows in the other fields.
On top of that, you can specify each column in your CSV and further format them as CSV, Date and Time, Excel Hyperlink, Number or Text fields.
You can find more detailed information on the Format CSV online help page.
Format CSV Setup screen

Result after Test in Extract action

NEW #1631: FORMAT TEXT / NUMBER / DATE / REPLACE TEXT – NEW OPTION: [ X ] Remove empty lines. This option is disabled by default.
NEW #1565: EXTRACT – REMOVE SPACES -> REMOVE: The “Remove Spaces” rule has been replaced by the Remove rule. This rule includes the following additional options:
– Remove blank lines
– Remove line separators
– Remove tabs
– Remove spaces
– Only keep characters with the option to define the characters to keep. For example: If you only keep characters “0123456789”, it will only keep the digits and will remove all other characters.
NEW #1607: EXPORT TO FOLDER: FILE INDEX – CSV FORMAT: We have added an option to disable CSV formatting in case the field in the File Index already contains a completely formatted CSV. This is the case when you merge columns extracted with the Extract Text (Azure Form Recognizer) rule with the new Format CSV rule (see version history notes #1430 and #1537).

NEW #1584: EXTRACT (AZURE FORM RECOGNIZER) – SEARCHABLE BARCODE OPTION: since the latest version of the Azure Form Recognizer engine also outputs barcode values, we have added an option to add those values in the Searchable PDF text layer to make barcode values searchable. The barcode values are returned in all supported models:
– Invoice
– Other Form
– Read
– Receipt
NEW #1576: IMPORT FROM FOLDER / EMAIL – CONFIGURABLE JPEG COMPRESSION SETTING: In a lot of actions, we need to update a PDF and apply JPEG compression in case of PDFs containing color or gray images. By default, we use a JPEG compression of 70 which provides good image quality with a reasonable file size. However, the JPEG compression was not configurable.
Now you can set the JPEG compression in the Import from Folder and Import Email action. By default, the JPEG compression is set to 70 but you can decrease or increase it. Higher numbers result in better image quality but larger files. The JPEG compression setting is used throughout the workflow every time an action needs to change a PDF.
Some actions, like the Convert to Multipage TIF action and Convert to Searchable PDF action (using the Tesseract engine), have their own Q-factor setting. This individual setting always takes precedent.
NEW #1591: NEW VARIABLES – { Page Number, [ FIELD NAME ] } : The variable { Page Number, [Field Name] } returns the page number in the document where the data in the specified field was found.
If the data in the field is spread over multiple pages, it returns the page number of the first line in the field.
Example use-case: A form contains 10 pages. You are interested in the page about the “Bank Details” with a big heading “SECTION 5: BANK DETAILS”. The form’s pages are not always in the correct sequence, meaning that the bank details can be on any of the 10 pages. You first use a Find Word with Mask / Words rule to find the words “SECTION 5: BANK DETAILS” and put the found words in a field called, for example, “KEYWORD”. If the keyword is found on page 7, then the variable { Page Number, KEYWORD } would return the value “7”.
Next, the page number can be used in a Find Selected Text or Extract Text (Azure Form Recognizer) rule to extract the data from the correct page. See version history note #1592 for more details.
NEW #1592: FIND SELECTED TEXT / EXTRACT TEXT (AZURE FORM RECOGNIZER) – VARIABLE PAGE NUMBER: We now allow a variable field to set the page number or page range to be extracted.
The use-case is about handling long forms where the pages are not always in the correct sequence. You would first find the correct page by using unique keywords only occurring on the page you are interested in. Next, you use the detected page in the Find Selected Text or Extract Text (Azure Form Recognizer) rule to extract the content of that specific page.
With the new { Page Number, [ FIELD NAME ] } variable (see version history note #1591) you can easily load the page of a detected keyword in a field and use that field to extract the full text of that specific page using the Find Selected Text or Extract Text (Azure Form Recognizer) rule.
After that, you can use traditional Find rules to extract data from that specific page.
NEW #1594: FIND WORD WITH TYPE / VALIDATE TEXT RULE – IBAN CHECK: A new IBAN Type has been added to check if an IBAN code is valid. More details about the check-logic are explained here: https://www.ibantest.com/en/how-is-the-iban-check-digit-calculated
NEW #1655 & #1676: EDIT – DIGITAL IMPRINTER: With the Digital Imprinter action, you can digitally imprint fixed text, field or metadata values or a QR code on the first page, on all pages of your documents or on an additional blank header sheet, automatically prepended to each document.
The product code in the CaptureBites pricelist is “CB-META-DGIM”.


You can compose the content of your Text and QR code value separately by combining fixed text with MetaServer field values or metadata values. The text can be printed in any font type, size and color.
The QR code size can be changed by setting its module size (the size of the small black squares in the QR code) and imprinted in a color of choice.
You can also accurately position the Text and QR code using left, right, top and bottom margins.
To avoid printing on top of existing text, you can add a white (or other color) banner on top or the bottom of the page and then imprint inside that banner.

To see a preview of your Digital Imprinter setup, you can simply press the “Test” button in the setup which will open an imprinted test PDF file in the associated PDF viewer.
If you are using MetaServer field values, press the “Test Values” button to set test values for a more accurate preview.

IMPORTANT: The imprinted text is embedded in the document image and cannot be removed with a PDF editor as opposed to a text layer that easily can be removed with a text editor.
NEW #1681: EXPORT TO DOCUWARE – SUPPORT TABLE FIELDS: We now support table fields in the Export to Docuware action. A DocuWare Table field expands in multiple column headers in the mapping list. Each column can be mapped with a MetaServer multi-line field.

ENHANCEMENT #1595: VALIDATE LARGE DOCUMENTS: PDF Files with more than 800 pages caused an error in Validation and showed an error:
“An exception has been thrown when reading the stream.”
We have increased the Max size limits and now large documents with up to 2000 pages can also be loaded.
More info for advanced users:
The limit can be adjusted manually by editing following config files:
C:\Program Files (x86)\CaptureBites\Programs\MetaServer\MetaService.exe.config
C:\Program Files (x86)\CaptureBites\Programs\Validation\Validate.exe.config
C:\Program Files (x86)\CaptureBites\Programs\Admin\Admin.exe.config
The entry that requires adjustment is:
“BasicHttpBinding_ITransferService” sendTimeout=”00:05:00″ maxReceivedMessageSize=”4294967294″
The current maxReceivedMessageSize of “4294967294” and should be able to cope with documents up to 2000 pages. If you ever have to handle even larger documents, increase the maxReceivedMessageSize parameter in all 3 config files.
After adjusting the values, MetaServer needs to be restarted from the desktop. Any connected clients need to be restarted as well.
ENHANCEMENT #1682: LICENSING: since this version, we have removed some elements in the license check that were often causing license mismatch issues with some users. It caused the “Computer Id mismatch” error, which required a manual reset of the license.
FIX #1585: IMPORT EMAIL: Emails containing scripts got stuck in the Preprocess document queue without any error. They are now correctly processed.
FIX #1588: IMPORT EMAIL: On some rare occasions, emails may have a wrongly encoded attachment Content-Type, which caused an error. To detect the attachment file type, we now first look at the extension of the file and only for files without extensions we look at the Content-Type entry in the email. Unknown file extensions are skipped.
FIX #1589: IMPORT EMAIL: Email Import from Disk (EML and MSG): { Import File Name } was not always correctly resolved and did not always return the original MSG or EML file name.
FIX #1646: KOFAX VRS – HOLE FILL: Exceptionally, the Hole Fill option caused an error on some specific pages:
“ProcessImage failed, result code: -289, error text: Host processor exception.”
This blocked the Kofax VRS action to do any further processing. We now handle this error gracefully and Kofax VRS continues working on other pages / documents.
FIX #1671 IMAGE FILE SIZE: Black & White image PDFs generated with the old and obsolete “AdultPDF “, feature images smaller than the PDF page and were incorrectly interpreted as color causing an increase of file size after processing. This fix handles Black & White PDFs generated with AdultPDF correctly.
FIX #1654: EXTRACT – SET FIELD VALUE: If you used the colon “:” as a segment separator to extract the 2nd segment in the below examples, the two first values, generated a leading space.

For example:
| Original | After “Set Field Value” rule |
| ADDRESS : 742 Evergreen Terrace, Springfield, OR 80085 | ” 742 Evergreen Terrace, Springfield, OR 80085″ |
| ADDRESS : 743 Evergreen Terrace, Springfield, OR 80085 | ” 743 Evergreen Terrace, Springfield, OR 80085″ |
| ADDRESS : 744 Evergreen Terrace, Springfield, OR 80085 | “744 Evergreen Terrace, Springfield, OR 80085” |
With this fix, the leading space in the first two values is now automatically removed.
Version 3.1(23) | 2023-07-26
NEW #1430: EXTRACT TEXT (AZURE FORM RECOGNIZER): The Azure Form Recognizer engine used in the new Extract (Azure Form Recognizer) rule works with prebuild models. The most important and impressive model is the “invoice” model which extracts header data and line items from any invoice without training or configuration.
This module requires an Azure subscription for a Form Recognizer resource which you can find under the “AI + Machine Learning” category. You can access https://portal.azure.com to create your resource. Documents processed with the invoice model are around 10$ for every 1000 pages.
The Extract (Azure Form Recognizer) rule also returns the full text value (= Document content) of each page that can be used in combination with standard MetaServer Extract rules for additional fields not covered by the prebuilt model and generates a fully searchable PDF using the full text output.
The Extract (Azure Form Recognizer) setup provides access to the General Available “2022-08-31 GA” version and the “2023-02-28-preview” version. We select the preview version by default. However, the preview version is currently only available for Azure Form Recognizer resources in the following locations:
– West Europe
– West US2
– East US
If your Azure Form Recognizer resource is created in another location, select the “2022-08-31 GA” version.
If you already have MetaServer and you want to add the new Extract (Azure Form Recognizer) module, you can order “CB-META-AZFR” from your reseller.
You can find more detailed information, pricing details, guides on how to apply for a resource and examples on the online help page.

Rule Setup with Test Results

Results, with CSV table showing the extracted line items, in Validation
NEW #1233, 1333, 1334 and 1415: IMPORT FROM WEB SERVICE: Added the “Import from Web Service” action to send documents to MetaServer using a REST API.
The Web Service and documentation is located in:
C:\Program Files (x86)\CaptureBites\Programs\MetaServer\Rest Service
Using the “Import from Web Service” action requires a license for the “CB-META-WBSI” module.

NEW #1452: VALIDATE – CHECK IF CONFIDENCE: We added a new option in all Validate rules: Check if confidence <= [ X ] %
Since we implemented the Azure Computer Vision engine and the Azure Form Recognizer, we get more accurate confidence levels for extracted data. This will allow to only validate values below a certain confidence level.
Confidence levels are only returned if the document went through one of the OCR engines.
When text comes from text-based PDFs (non-scanned PDFs generated by software like Word, etc.), confidence levels will always be 100%.
When text comes from the text layer of a scanned searchable PDF, we literally extract the text layer which does not have any confidence info and confidence levels will also be 100%.
When a field is blank, the confidence level will be equal to 0%.
The “Check if not blank” option takes precedent and all fields with a value regardless their confidence will need to be checked.
If you only want to check fields with a value below a certain confidence but also allow blank fields, just disable the “Required” option and only enable the “Check if confidence <= [ X ] %” option. Blank fields won’t need to be validated.
If you also want to check blanks, also enable “Check if blank” option.
NEW #1542: EXTRACT TEXT (AZURE COMPUTER VISION) / EXTRACT TEXT (AZURE FORM RECOGNIZER) / CONVERT TO SEARCHABLE PDF – PROXY SETTINGS: Proxy Settings have been added to the following rules:
Extract text (Azure Computer Vision)
Extract text (Azure Form Recognizer)
Convert to Searchable PDF (using the “Azure Computer Vision” engine)
NEW #1549: ADMIN CLIENT – ERRORS TAB: It is now possible to change your field values in the Admin Client‘s Errors tab and retry the action using the new value. This is not possible in the Operator client.
For example, when an invalid date (<1900) fails to export to SharePoint, you can correct the date in the Admin Client’s Errors tab and succesfully submit the document to SharePoint.
ENHANCEMENT #1425: VALIDATE CSV – NUMBER: We have added a minimum number of decimals entry similar to the Number field.
ENHANCEMENT #1550: VALIDATE CSV: We added a new top level “Always check” option. When enabled, the cursor will move to the first cell if none of the cells have to be checked. If any of the cells have to be checked, it would jump to the cells to be checked as usual.
ENHANCEMENT #1555: KEEP BLANK LINES IN FORMAT TEXT, NUMBER, DATE RULES: The Format Text, Number and Date and Time rules will keep any blank lines to make it possible to merge them in an invoice line item CSV. These format rules can be used to format columns resulting from the Extract Text (Azure Form Recognizer) rule’s Invoice model.
ENHANCEMENT #1451: CONVERT TO MULTIPAGE TIF: the Convert to Multipage TIF action is now running on 4 cores in parallel instead of just 1 core.
ENHANCEMENT #1568: IMPORT FROM FOLDER: when creating a new Import from Folder action, we have changed it so that the “Fit” defaults to only JPG and PNG and TIF is left unchecked.
The “Fit” option is mainly used with smartphones producing JPGs. By default, we now leave TIF untouched. This is to avoid problems with large plans scanned in TIF format which should not be resized
FIX#1223& #1445: EXTRACT – FIND: The “Delete duplicates” option did not work when the duplicate words were on the same line.
FIX#1286: EXTRACT TEXT (AZURE COMPUTER VISION): Using the Azure on-premise container showed an error when the endpoint contained a trailing “/”.
FIX#1473: IMPORT: Some Text Based PDFs generated an error: “Input data is not recognized as valid pdf.” We upgraded our PDF library to DEVEX V22.2 and this is now fixed.
FIX#1450: EXTRACT: Reading text-based pdf generated by “typeset.sh” were not showing a section of the page.
FIX #1471: EXPORT TO DATABASE: If two database exporters were used and all settings were identical but the server name, then MetaServer sent documents to the last used server.
FIX #1444: IMPORT EMAIL – OFFICE 365: An erratic error “Already connected to the server.” made the import action red. We added a call to Disconnect() before a retry.
FIX #1454: IMPORT EMAIL – OFFICE 365: All Office file attachments (xls, xlsx, doc, docx) were considered invalid.
FIX #1449: EXPORT PROCESSED SET: An Export to Email license was required even if the export processed set action only exported a file on disk.
FIX #1470: EXPORT TO FOLDER: When exporting to an AS400 FTP server, an error occurred “Error: The requested operation is not supported.” This was because the AS400 FTP server does not support the SIZE command. For FTP servers not supporting the SIZE command we now use an alternate method.
FIX #1479: VALIDATE – DATABASE LOOKUP: When a DB lookup fields was not required AND the “Update Database” option was enabled and the “Field” was left empty, an error “The given key was not present in the dictionary” occurred.
FIX #1431: VALIDATE: When you made the operator or admin client window size smaller, then there were no small icons available for the “Compact View” and “Font Size” buttons, hiding the icons completely.
FIX #1484: VALIDATE: When you had more fields than the display could vertically show, and you clicked in the bottom part of the vertical scroll bar, the focused field was scrolled away out of visual scope.
FIX #1482: VALIDATE – SUBMITTING VALIDATED DOCUMENTS: Some documents were not submitted correctly after being validated and data was lost. This happened since version 3.1.22 when a unique combination of things occurred:
1) An operator opened the document list and the “Hide Locked” option was DISABLED
AND
2) Another operator presses “OK” on the last field of a document
FIX #1486: VALIDATE / ORGANIZER: OPEN DOCUMENT LIST: Cancelling the loading of any of the “Open Document” lists always caused an error “Object reference not set to an instance of an object.”
FIX #1477: EXPORT TO WEB SERVER – APE: When an attempt was done to send default values for Azienda (0000000) & TypoDoc (.VASCHETTA), the keys were not sent.
FIX #1478: IMPORT FROM WEB SERVICE: When reporting an error, the webhook of the first “ImportFromWebService” is called, even if the document wasn’t imported from a Web Service. If a document was imported from a folder, no webhook is called anymore.
FIX #1472: WORKFLOW LOG MENU: Log Email Communication is more accurately renamed to “Log Email & FTP Communication”.
FIX #1497: EXPORT TO DATABASE: Exporting to DateTime fields failed on Italian Locale SQL Server
We were sending below syntax to update a datetime field which worked OK on a US locale system:
INSERT INTO [metaserver_stats] ([date_export]) VALUES (‘2023-05-18 18:45:22’).
We now send universal ISO 8601 formatted dates and it also works on a SQL server with Italian Locale (note the T between the date and time part):
INSERT INTO [metaserver_stats] ([date_export]) VALUES (‘2023-05-18T18:45:22’)
FIX #1495: EXTRACT TEXT / EXTRACT TEXT (ACV): Testing Small Size Documents in Extract Text (TOCR or Azure Computer Vision) using the cached OCR result caused an error: “Duplicate attribute.”
FIX #1540: FAILURE TO DELETE TEMP FILES: When antivirus locked filename.pdf.SERVERNAME.RESERVED file, then the import action turned red with an error “The process cannot access the file”
FIX #1566: ORGANIZER: in some cases, the Merge function merged too many documents.
FIX #1575: REFRESH LICENSE: If you first paused the server, then did a refresh license, the refresh timed out with an error. On a production system with a queue that never gets to 0, it is highly recommended to first pause the server to make all actions yellow and then Refresh. This procedure works correctly now.
FIX #1581: MS SQL CONNECTIONS: We had an issue related to exporting to a Dev SQL Server and a Production SQL Server with identical tables on each SQL server. To do this correctly, we had to compare the SQL Server URL to open a new connection when the SQL server was different. This change had a bug causing the code to think each connection was different piling up all the connections, causing an error “max pool size was reached” after MetaServer reached 100 connections.
Version 3.1(22) | 2022-03-01
NEW #719: VALIDATION – FONT SIZE: New button in validation’s ribbon called “Font Size”. You can now change the font size of your fields in validation for a more comfortable validation view on higher resolution screens.
You can choose between Large, Medium or Standard font size. The last setting is remembered on each operator client.

Standard

Medium

Large
NEW #1403: VALIDATION – COMPACT VIEW: New toggle button in validation’s ribbon called “Compact View”. You can now remove white spaces between all your validation fields. This will show the maximum number of fields in your validation window’s field panel.
The last setting is remembered on each Operator Client.

Normal view

Compact view
NEW #1353: ORGANIZER / VALIDATION – OPEN DOCUMENTS: We’ve added an option to hide / show locked documents.
A locked document is a document opened by an operator for Organizing or Validation. Locked documents are displayed in italic font, indicating that they cannot be opened.

NEW #1402: VALIDATE SETUP – CYCLE THROUGH INVALID FIELDS: When this option is disabled, pressing the ENTER or OK button will put the focus on the first field to be validated.
When the option is enabled (= default) pressing the ENTER or OK button will put the focus on the next field to be validated.
Once all fields are validated, the focus cycles back to the first field that remains to be validated. This is a more natural way of navigating through invalid fields, so we’ve enabled it by default.
NEW #1399: EXPORT WEB SERVER – APE: We have added a new web server called APE for the Italian market. See https://www.apesrl.com/
You can map following APE fields with MetaServer fields:
– Azienda
– Tipodoc
– Stringa
– Indexes[4] to Indexes[8]
NEW #1416 & #1421: EXTRACT / VALIDATE – DB LOOKUP: It is now possible to set the precision of decimals when using db lookup during extraction and validation. The new option is called “Digits after decimal: [ 2 ]” and is located in the “Field Mapping” tab of the following Extract and Validate rules:
Find Database Lookup
Find Word with Mask / Words (in the Accept words from database setup)
Validate Database
And the following Task actions:
Sync MetaServer Database
The precision of decimals can be changed between 0 and 9 digits after the decimal.
By default, MetaServer uses the decimal precision as set in the Windows regional settings, which is typically 2 digits after decimal. This setting affects the precision of the following database field types: Choice, Decimal, Numeric, Number, Real and Float.
IMPORTANT: How is this different from the Hide digits after decimal option?
The Hide digits after decimal option was specifically designed to be used with an Oracle DB over ODBC. There, the Datatype NUMBER(14) are an INTEGER but they are reported as DECIMAL. This is a nuisance to lookup via these values because, for example, an order number like 123456 is returned as 123456.00. To work around the ODBC problem, you can enable this “Hide digits after decimal” option.
This hides the digits after the decimal for the lookup field. Not for the mapped fields. If you would set the new Digits after decimal option to 0, it would hide the digits for all decimal fields, lookup AND mapped.
NEW #1394: UNINSTALLER – SILENT UNINSTALLMENT: You can now run the uninstaller silently by adding a “/s” command.
For example, the following command will uninstall the Operator client silently:
C:\Program Files (x86)\CaptureBites\Uninstallers\3.1 MetaServer – Operator Client\Uninstaller.exe /s
NOTE: Running an installer silently was already possible using the same technique.
NEW #1284: NEW VARIABLE – FIELD LINE COUNT: For example, if the field “Items” holds 12 lines, { Field Line Count, Items } returns “12” as a value.
ENHANCEMENT #1422: EXTRACT – FIND LINE WITH LINE NUMBER: The Find Line with Line Number rule now accepts a field that holds the line number.
The use case is parsing an unknown number of lines in a field using a counter and a Distribute Loop.
ENHANCEMENT #1425: VALIDATE NUMBER: You can now set both the minimum and maximum required number of digits after the decimal.
ENHANCEMENT #1398: EXTRACT / VALIDATE – DATABASE LOOKUP: you can now select “is not equal to” in the DB Lookup filter.
For example, if you want to select Operator 1 and 2 for Double Entry and they cannot be equal, you can set a filter for each lookup field to make sure that Operator 1 is not equal to Operator 2 and vice versa.
ENHANCEMENT #1406: SELECT SERVER: We have simplified the way to connect to a MetaServer manually. Now, you just need to enter the friendly name or IP address of the computer where the MetaServer service runs on to connect to it.
ENHANCEMENT #1411: EXPORT TO SHAREPOINT: We have added a “Type” column to the Field Mapping List indicating the column type: Text, Note, Number, DateTime or Boolean.
ENHANCEMENT #1410: EXPORT TO SHAREPOINT: If a column cannot be updated, typically because of an invalid value for the column’s data type, the error message will clearly indicate which column this error applies to.
Examples:
1) Column ‘Amount’, of type ‘Number’: Input string was not in a correct format.: ‘1000 EUR’
2) Column ‘Date’, of type ‘DateTime’: Year, Month, and Day parameters describe an un-representable DateTime.: ‘2023-02-31’
For Boolean columns (Called Yes/No Column in SharePoint), values had to be TRUE or FALSE, they can now also be YES or NO. The values are also not case sensitive, so, yes, Yes, true and True would also pass.
ENHANCEMENT #1413 & #1414: EXPORT TO SHAREPOINT – ON PREMISE: We now automatically retry if SharePoint times out with following errors:
– The operation has timed out
– The request failed with HTTP status 401: Unauthorized
– Unable to connect to the remote server
MetaServer loops 5 times, waiting for 2, 4, 8, 16 and 32 minutes, up to 1 hour. After 1 hour, the action turns red, the document is moved to the Errors tab and an Email Alert is sent (if enabled for that workflow).
The Export to SharePoint action will turn orange during a retry loop reporting the next retry:
Communication error: retry in (x) minutes.
ENHANCEMENT #1420: PUBLISH WORKFLOW – NEW DEFAULT: To avoid accidental updates of documents in the queue when publishing a workflow, we have set the default to “Don’t update workflow” instead of “Use new workflow”.
If you select “Don’t update workflow” by mistake it can easily be corrected. Selecting “Use new workflow” by accident is irreversible.
ENHANCEMENT #1397: EXTRACT (AZURE COMPUTER VISION): The Error “The remote server returned an error: (410) Gone” is automatically retried until the Azure server is up again.
ENHANCEMENT #1386: EXPORT TO FOLDER: We have added a new option in the Export to Folder action’s “If file exists” options called “Skip”.
When you select “Skip” for files that already exist, the file would simply not be exported. In most cases, this is a better option than selecting “Overwrite”, because there will never be a file locking problem if, for example, the file is already open in a PDF viewer.
FIX #1385: EXPORT TO FOLDER: When selecting “Use Sequence Number” for files that already exist, we don’t allow a file name without a sequence number anymore.
FIX #1400: EXPORT TO ALFRESCO: Passwords containing curly brackets are now accepted. Previously, MetaServer interpreted passwords with curly brackets as a field. This triggered a pop-up to enter the password a second time. This is now fixed.
FIX #1286: EXTRACT (AZURE COMPUTER VISION) – ON PREMISE: An error occurred when the endpoint contained a trailing /. Endpoint http://localhost:5000 works but http://localhost:5000/ failed with an error: Value cannot be null. This is fixed.
FIX #1419: LANGUAGE SELECTION: Switching the Operator Client’s language switched the way the decimal symbol was displayed. This is, of course, unrelated and decimal symbols should be displayed according to Windows regional settings and not the language of the Operator Client. This is now fixed.
FIX #1387: SERVER – DATA DRIVE: On some systems, when you pressed the Data Drive button, you got an “Unhandled Exception”.
FIX #1417 & #1418: LOCALIZATION: Some new dialogues and messages from the previous versions were not yet localized.
FIX #1434: AZURE COMPUTER VISION: Azure Error 410 “gone” actually means that the used preview model has been deprecated by Microsoft. Because of this, we do not retry anymore when this error occurs and immediately send the document to the errors tab with a more descriptive error: “Preview version 2022-01-30-preview has been deprecated. Please select the General Available model.”
This fix was published in version 3.1.22.46.
Version 3.1(21) | 2022-12-22
NEW #1326: VALIDATE CSV: This new validation rule allows you to validate a field containing multiple lines separated by comma’s or semicolons.
If you have a fixed table, you can use MetaServer to extract all the lines in the table and replace the spaces between the values with commas (or semicolons).
For example imagine a table like this:

“Hyundai”,”Santa Fe Hybrid/Hybrid Blue”,”SUV”,”1.6L I4″,”4WD”,”32-34″,”$33,650″
“Hyundai”,”Sonata Hybrid/Hybrid Blue”,”Sedan/Wagon”,”2.0L I4″,”FWD”,”47-52″,”$27,950″
“Hyundai”,”Tucson Hybrid/Hybrid Blue”,”SUV”,”1.6L I4″,”4WD”,”37-38″,”$30,900″
“Jaguar”,”F-PACE P340/P400 MHEV”,”SUV”,”3.0L V6″,”4WD”,”22″,”$64,800″
“Jeep”,”Wagoneer 4WD”,”SUV”,”5.7L V8″,”4WD”,”17″,”$61,995″
“Jeep”,”Wrangler 4dr 4×4″,”SUV”,”3.6L V6″,”4WD”,”21″,”$34,045″
etc.
The new Validate CSV rule converts the CSV to a table. You set a name for each column and each column can be defined as a Text, Number or Date field with all the usual format checks. Database lookup columns are not supported yet. In Validation, the above table would look like this:

If you select a line in the table, the viewer automatically jumps to the correct page and highlights the line where the data came from. Thanks to validation rules, you can easily check blank cells or cells with invalid data by just hitting the ENTER key which will jump from invalid cell to invalid cell.
As long as there are invalid cells or cells to be checked, the table will have a red frame.
Once validation is finished, MetaServer updates the CSV based on the edits in the table, ready for export to a system of choice.
For more detailed information and tips, please refer to the Validate CSV online help page.
NEW #1380: IMPORT FROM FOLDER: The “Create a document per subfolder” feature now also supports PDF files and Office files. Before, you could only create documents from a subfolder of JPG, TIF or PNG files. PDF and Office files are now also supported.
NEW #1241: EXPORT TO ALFRESCO: Many improvements and better performance:
1) The connector now always uses CMIS 1.1
2) You can select between Ticket (default) or Basic Authentication
3) You can disable chunking by disabling the “Upload file in chunks” option. Chunking is ON by default. And you can set the chunk size between 64KB and 4MB (default if the setup is opened for the first time: 1MB)
4) We now get the content type by ID. Index fields were already retrieved by ID.
5) Removed redundant parsing of parent when creating a folder.
6) The connector now checks out the document at creation and checks in when the document is fully available. This to avoid conflict with external scripts moving the document after export.
7) We added optimized parsing of aspects and reduce the number of calls. We now only ask info about the aspects in use during export.
8) We don’t parse from the root anymore but from the highest level folder.
ENHANCEMENT #1245: CONVERT TO SEARCHABLE PDF WITH AZURE COMPUTER VISION: We now support parallel page processing in the Convert to Searchable PDF action.
Next to the number of conversion cores, we’ve also added the number of parallel pages to be processed.
The number of conversion cores determines how many documents will be processed in parallel. We don’t advice to push this higher than the number of physical cores in your computer to avoid a system overload.
IMPORTANT: The conversion cores multiplied by the number of pages converted in parallel should not exceed the number of physical cores in your computer.
The number of pages of a single PDF that are converted in parallel are set with the new “Convert x pages in parallel” setting.
“Small” documents (< 20 pages) process faster by increasing the number of conversion cores and leaving the number of parallel pages converted low (between 1 and 3).
“Large” documents (> 20 pages) process more efficiently by keeping the number of conversion cores low (1 or 2) and setting the parallel pages converted higher.

IMPORTANT: In general, we highly recommend performing a CPU test by watching the CPU performance in Task Manager while processing documents with MetaServer.
If there is an occasional peak of 100%, like the below image shows, that is OK. But if the CPU is at 100% capacity for long stretches of time, your system will start generating errors. In that case, decrease the number of cores or pages in parallel or both in the Convert to Searchable PDF setup.

NEW #16: VALIDATE – CONDITIONAL LOGIC: in this initial implementation of conditional validation logic, you can set a field to “Always Check” or “Not Always Check” depending on the value of another field.
For example:
If {STATUS} = MARRIED,
THEN SET {SPOUSE NAME} ALWAYS CHECK option
If {STATUS} = SINGLE
THEN CLEAR {SPOUSE NAME} ALWAYS CHECK option


ENHANCEMENT #1321: VALIDATE – COLORED BACKGROUND HIGHLIGHTED FIELDS: We now color the background of a focused field with light blue to make it stand out more. This is useful if you have many fields and you quickly want to find the field with the focus.

NEW #1324: VALIDATE – COPY AND PASTE ZONE SETTINGS: we added an option to the settings of each validation rule to allow you to copy and paste the Zone from one validation rule to another to make sure all highlight zones are absolutely identical.
NEW #1325: EXTRACT – FIND WORD GROUP – RADAR MINIMUM DISTANCE & INSERT BLANK IF EMPTY: two new options have been added to the Find Word Group with Mask / Words Extract rule:
– Radar Minimum Distance (default = 0)
– Insert blank if empty (default = OFF)
To find specific columns in a list, you can use an anchor column with the Find Word Group rules.
For example, we have a list with 6 rows extracted from a document:
| Type | Make/Model | MSRP |
| HEV | Hyundai Santa Fe Hybrid/Hybrid Blue | $33,650 |
| HEV | Hyundai Sonata Hybrid/Hybrid Blue | |
| HEV | Hyundai Tucson Hybrid/Hybrid Blue | $30,900 |
| HEV | Jaguar F-PACE P340/P400 MHEV | $64,800 |
| HEV | Jeep Wagoneer 4WD | |
| HEV | Jeep Wrangler 4dr 4×4 | $34,045 |
Assume you want to extract the price column and preserve the empty lines, if any are present.
You could use the column with the word “HEV” as the anchor column and measure the distance between the end of the word “HEV” and before the prices. This would be your Minimum Radar Distance.
Then, you measure the distance between “HEV” and after the prices. That would be your Maximum Radar Distance.
Finally, you’d check the new Insert blank if empty option to insert an empty line for cars without a price.
The result would only contain the prices and blank lines where there was no price resulting in exactly 6 lines.
$33,650
$30,900
$64,800
$34,045
You can use the same method to extract the “Make” and “Model”, which will also result in 6 lines:
Hyundai Santa Fe Hybrid/Hybrid Blue
Hyundai Sonata Hybrid/Hybrid Blue
Hyundai Tucson Hybrid/Hybrid Blue
Jaguar F-PACE P340/P400 MHEV
Jeep Wagoneer 4WD
Jeep Wrangler 4dr 4×4
Fields with the same number of lines can be merged with a Set Field Value rule.
With this technique, you can extract the line items column by column, apply Replace Text rules on individual columns and then merge them in a CSV format. After that, you can validate the CSV value with the new Validate CSV rule (see #1326).
NEW #1343: SERVER – INFO TIP: next to the “Send warning when folder is not available for [x] minutes” option in the Server tab, we added an info tip to give a more detailed explanation of the option:
If the connection to a network folder fails, then MetaServer will try to reconnect indefinitely and will send a warning message after the specified number of minutes.
You can adjust the warning email details and recipient in the workflow’s “Email Alert” settings.
FIX #1314: IMPORT EMAIL – AUTO-RECOVER GMAIL & OFFICE 365 CONNECTIONS: Gmail & Office 365 connections did not auto-recover from an internet interruption and turned red after a few minutes.
FIX #1318: SCALE PAGES – AUTO-RETRY: when scaling a lot of documents, very infrequently an error occurred “A document could not be processed”. Just retrying the document, made it work. We now retry automatically.
FIX #1348: VALIDATE/ORGANIZER – OPEN DOCUMENT LIST: if you closed the “Open Document List” with Cancel or the “X” button in the title bar, a document is loaded. This was unexpected. If you now cancel the “Open Document List”, no document is loaded.
To open a document, just double-click a document or press OK in the Document List.
FIX #1349: EXTRACT BARCODE: when you extract all barcodes from a PDF with over 50 pages, the barcode reader sometimes showed an error “Extract Barcode failed”. This only happened during extraction and never during separation. We adjusted the code to use the same method in extraction as we already used in separation.
FIX #1362: VALIDATE NUMBER: an “unhandled exception” error was triggered during validation where you click-selected text in a Number field with:
– “Amount” formatting enabled
– Replace text enabled
This was related to formatting logic that created empty lines for lines without any numbers. We now ignore these lines.
Version 3.1(20) | 2022-09-07
NEW #63: IMPORT FROM FOLDER / IMPORT EMAIL: OFFICE DOCUMENT SUPPORT: Word and Excel documents (XLS, XLSX, DOC, DOCX) can now be imported from folder or from an email inbox as attachments. The office documents are automatically converted to PDF documents and used for further processing with MetaServer such as Separation and Extraction. You have the choice to export the original Office Document and / or the PDF version.

When importing from email, ZIP and RAR attachments containing office documents are also supported.
NOTE: To make use of the “Import Office Document” feature, you need to have a license for the “Import Office Documents” module with product code “CB-META-OFFI”.
If the module is not licensed and you enable the Word and / or Excel file type in an Import action, the importer will show an error in the Server tab as soon as it tries to import an Office document: “Module ImportOfficeDocuments is not licensed.”
To avoid the error, disable the Word and Excel “File type” options from your Import Folder and Import Email actions or purchase a license of the “Import Office Document” module.
The { Document File Type } variable can now be one of 14 following values:
Unknown
Excel
JPG
TIF
PNG
PDF Unknown
PDF Image
PDF Image with text
PDF Text
PDF AcroForm
PDF XFA
PDF Corrupt
PDF Password Protected
Word
NEW #1230 & #1266: CONVERT TO SEARCHABLE PDF – SUPPORT AZURE COMPUTER VISION: the Convert to Searchable PDF action now also supports Azure Computer Vision engine, next to the already supported Tesseract engine.
The Extract Text (Azure Computer Vision) module needs to be licensed to make it possible to use Azure Computer Vision during run time for the Convert to Searchable PDF action. If the user selects “Azure Computer Vision” while it is non-licensed and processes a document, an error message will show in the errors tab with the notice that Azure Computer Vision is not licensed.
The benefit of creating Searchable PDFs with Azure Computer Vision is that Azure Computer Vision can also make handwritten and degraded machine printed text searchable.
The standard Tesseract engine remains free as before.
Multi-Core processing is free for Searchable PDF and does not require the purchase of additional core licenses.
You can now also run Searchable PDF up to 24 cores. Of course, please note that the machine you are running MetaServer on needs to have a corresponding number of cores.
If you use Tesseract, your machine should have the same amount of cores as specified in the setup. If you use Azure, this should be half of the number of cores as specified in the setup.

NEW #1216: IMPORT EMAIL – SUPPORT FOR LINKED EMAIL OUTLOOK ACCOUNTS: In Outlook 365, you can set mailbox permissions to allow read/write access to the mailbox of one or more other users.
To import from such linked account, just sign in with the main account and enter the linked account you want to import from in the Mailbox field. If you leave the Mailbox field empty, MetaServer will use the main account to import from.
You can find more info about mailbox permissions here:
https://docs.microsoft.com/en-us/microsoft-365/admin/add-users/give-mailbox-permissions-to-another-user?view=o365-worldwide
NEW #1231: IMPORT EMAIL – RAR ATTACHMENTS SUPPORT: You can now also import RAR attachments. ZIP attachments were already supported since the previous version (3.1.19).
Automatically, any RARs are unRARred and any PDFs, TIFs, JPGs, PNGs, Excel and Word files contained in the RAR are imported. Each file will be considered as an attachment.
NEW #1277: IMPORT EMAIL – NEW VARIABLE: a new variable { Email Attachments List } has been added. This lists all attachments and their extensions of an imported email.
For example:
Sale LX-MLO.docx
PRJINV000064170.pdf
PRJINV000066398.pdf
JSSI0045163 Statement 120722.xlsx
General Conditions.txt
NEW #1032: EXTRACT TEXT (AZURE COMPUTER VISION) – COLOR DROPOUT: We added a color dropout option in the processing section of the Extract Text (Azure Computer Vision) action setup.
You can select up to 3 dropout colors. Each selected color has its tolerance. With the Test button, you can see the effect after dropping out the selected colors in the right preview windows.
To reset all dropout colors to white (off), you can use the “Reset All Colors” button.
NOTE: The filtered image is only used temporarily to improve text extraction. The processed image keeps all the original colors.

NEW #176: IMPORT FROM FOLDER – PRIORITIZE OPTION: If you enable the new Prioritize option in an Import from Folder action, then any documents imported through this action will overtake other documents in the processing queue.
In the Server tab, you can set the “Priority Queue Limit” to specify the maximum number of documents that can be imported in priority mode. Priority documents can only overtake documents that are scheduled for processing. A document that is in the middle of being processed cannot be overtaken.

In the Server tab, we added a “Priority Queue Limit” setting (between 1 and 250). The “Priority Queue Limit” sets the maximum number of documents that can be imported in priority mode. When the limit is reached, MetaServer pauses the import of more priority documents until imported priority documents are completely processed.
The “Priority Queue” works independently from the main import queue. If the overall Import Limit is not reached but the “Priority Queue Limit” is reached, priority documents need to be processed first before additional priority documents can be imported.

We also added an “Imported with priority” counter in the Counters pop-up. This enables you to check how many documents are imported in priority modus. You can also check if the Priority queue limit is reached.
The current Imported counter continues showing all imported documents (normal + priority) + their processed sets (if any). We also added the “Imported with priority” counter to the monitoring file.

NEW #774: VALIDATE – NOTE: A Note field can hold multiple lines. The setup is similar as for a Text field but without the double entry and the sticky features. Below the zoom parameter, there is a new setting called: Height: [ 5 ] lines
The default “Height” of a Note field is 5 and can be increased or decreased with a spinner control. If the Note field contains more lines than the specified height, a vertical scroll bars makes it possible to view the other lines during validation.
Each line in the Note field needs to comply to the defined mask or check.
Because the ENTER key is already used to OK the document in Validation, you should use CTRL+ENTER to create a new line in a Note field during validation.


In the above example, on a marriage certificate, the original address of the groom is often the same as his father’s. In that case, the already filled out values of the groom can be used in the groom’s father’s fields.
This means that the father’s address fields would have the Duplicate button option enabled to duplicate the Groom’s address fields with a single click.
Button Setup:


NOTE: For Number and Date fields, these already have the Calculated option with which you can accomplish the same effect.
NEW#1291: VALIDATE – IMPROVED DOUBLE ENTRY LOGIC: The “Double Entry” logic now supports multiple operators.
Validation can be set up to validate / keys all data by operator 1. Operator 2 then revalidates / re-keys the data and instantly compares the value with the value entered by the first operator.
When there is a mismatch, operator 2 has the following options:
1) Hit SHIFT+ENTER and the value they entered is accepted despite the difference with operator 1’s value. The cursor would also jump to the next field to validate. This is the case where operator 2 overrules operator 1 and believes operator 1 made a mistake.
2) Hit ALT+ENTER to duplicate operator 1’s value in field 2 and the cursor would jump to the next field to validate. This is the case where operator 2 admits that operator 1 got it right and takes over operator 1’s value.
3) Continue repairing the field value. This is the case where operator 2 realizes that neither his value nor operator’s 1 value is correct. After the operator made any changes and hits ENTER, a mismatch is checked again and we go through the above logic again.
For example, operator 2 entered “DRIVER” while operator 1 entered “TRUCK DRIVER”:

As soon as operator 2 hits the ENTER key, operator 2’s value is revealed and a pop-up warns that there is a mismatch:

Only by applying 1 of the 3 options we’ve mentioned, can the loop be broken.
The final output will be operator 2’s values.
ENHANCEMENT #986: EXTRACT TEXT (AZURE COMPUTER VISION) – OPTIMIZED RESULTS BUFFERING DURING TESTING: Most settings do not require to reload the image in Azure. They only reprocess the same Azure text output differently.
Before, any change to the settings reprocessed the image with Azure. This is now improved and only settings that affect the raw OCR result will rerun the Azure Read process. Such changes are: Key, Endpoint, Location, Model, Deskew, Auto-Rotate and Color Dropout. Modifications to other settings will make use of the buffered OCR result.
ENHANCEMENT #1287: IMPORT EMAIL / IMPORT FROM FOLDER: By default, we now enable the “Replace invalid…” and “Replace password protected…” options when you add an Import Email action. This turned out to be the preferred setting in most workflows.
ENHANCEMENT #1247, #1278, #1288: IMPROVED EMAIL ARCHIVING LOGIC: Archiving is the process of saving the complete email in the email system, in a specific IMAP folder after all the attachments of an email are completely processed by MetaServer.
You can define the archiving method for 4 distinct cases:
Emails:
1) With valid attachments
2) Without valid attachments
3) Without attachments
4) With all valid attachments deleted
Please refer to the Import Email help page for a detailed description of each condition. These descriptions are also displayed when hovering over the info tip in each of the archiving tabs.

As a reminder { Document File Type } can be one of 12 following values:
Unknown
Excel
JPG
TIF
PNG
PDF Unknown
PDF Image
PDF Image with text
PDF Text
PDF AcroForm
PDF XFA
PDF Corrupt
PDF Password Protected
Word
{ Document Source } can be one of three values:
Imported Document
Attachment
Email Body
FIX #1219 & #1232: IMPORT EMAIL: We replaced the Valid and Reject conditions with three more descriptive conditions:
1) with valid attachments
2) with invalid attachments
3) without attachments

Rejected emails were in fact all emails without attachments and with invalid attachments. These two kind of rejected emails have their own condition output now. Old workflows that used the Reject condition are automatically converted to use the “with invalid attachments” and “without attachments” conditions instead.
Also, the conditions were not always correctly applied and some emails with invalid attachments or without attachments went through the valid condition after all.
The condition of each email is also stored in a new variable called { Email Import Condition }. It can have one of the following three values identical to the conditions displayed in the workflow UI:
1) with valid attachments
2) with invalid attachments
3) without attachments
Finally when an email has no attachments or invalid attachments, the email body PDF is generated so something can be displayed in the Organizer or Validation if you choose to do so.
FIX#1279 & #1282: IMPORT EMAIL: When an email with corrupt or password protected attachments was imported with the Email body and attachments import mode selected (= all attachments are combined in a single PDF), then the “Processed Sets” queue froze because it was not capable of merging corrupt or password protected PDFs.
With this fix, all correct PDFs are correctly handled and all corrupt PDFs are replaced with a red warning “File Not Valid” PDF and any password protected PDFs are replaced with an orange warning “File is Password Protected” PDF.
You can then handle corrupt and / or password-protected PDFs in an exception process. After separating the combined set, you can easily identify corrupt or password protected PDFs with the “Document File Type” parameter which will contain the value “PDF Corrupt” or “PDF Password Protected”.
FIX#1276: IMPORT EMAIL – BODY: The { Email Body Text } variable did not contain line separators when displayed in a Note field in Validation.
FIX#1252: EXTRACT (AZURE COMPUTER VISION): Very infrequently (once every 10000 pages) ther following error occurred:
“Extract Text (Azure Computer Vision): Could not find file ‘C:\CaptureBites\MsData\Documents\2022\08.10\16.22.29.536\Temp\7ab652a3-b5fa-4878-9e35-418688b3728c_3_1\Results.CBMSOrganize’.”
The modification consists of additional error logging only. This additional logging is automatically enabled and cannot be turned off.
If an error occurs during future Azure activity, please browse to the following folder:
..\CaptureBites\Programs\MetaServer\Data\Log\yyyy\mm\AzureTrace nnn
The additional logging will allow us to identify the root cause.
FIX#1251 & #1275: EXTRACT (AZURE COMPUTER VISION): Once or twice a month, the following may happen:
1) The Azure service may be unavailable and an error occurs: “The remote name could not be resolved: ‘xyz.cognitiveservices.azure.com'”.
2) Error: “Could not load file or assembly…”
We now retry with intervals of 5 minutes indefinitely until Azure is online again. If the Convert to Searchable PDF, Extract or Separate action is in an infinite retry mode because of this, the action is highlighted with orange color in the Server tab.
FIX #1293: EXTRACT / SEPARATE / CONVERT TO SEARCHABLE PDF – AZURE COMPUTER VISION SEARCHABLE PDF: Azure Searchable PDF as produced by the Separate, Extract or Convert to Searchable PDF action, used transparency on the hidden text objects. This prevented these PDFs to be converted to PDF/A-1b, a standard that does not support transparency.
We disabled transparency on the hidden text objects, not causing any visible difference because the text was hidden anyway. Now, Azure Searchable PDFs can be output as PDF/A-1b with the Convert to PDF/A action.
FIX #1300: WORKFLOW DEFINITION: You could not add an Apply Separation & Page Processing action straight after a Validate action. It caused an unhandled exception error. This is fixed.
This is useful when you import emails with the Email body and attachments mode selected. The Import Email action puts virtual separators between each attachment of the email. You can then inspect the email with all its attachments during Validation, add some field data and then split the email in individual attachments with the Apply Separation & Page Processing action.
FIX #1292: VALIDATE: If you defined replacements or removed spaces in the Select Text / Edit text option, they were always applied even if you had switched off the Edit text option.
FIX #1297: VALIDATE – DATABASE FIELD: If the Database field was “Read only”, the grayed out “Always check” option still applied while it should not.
FIX #1295: OPERATOR / ADMIN CLIENTS: We disabled the ALT key to display shortcuts in the ribbon. This conflicted with double key entry shortcuts during Validation.
FIX #1290: EXTRACT – RESERVE RULE: The Reserve Rule did not overwrite a previous reserve rule.
FIX#1220: EXPORT TO SHAREPOINT ON PREMISE: Connecting to SharePoint On Premise failed with an error “NetworkCredential: Sequence contains no elements”.
FIX#1206: EXTRACT TEXT (AZURE COMPUTER VISION): When Azure Computer Vision extraction was performed with the Convert page(s) to searchable PDF option on, and the Use searchable text layer if present option off, the existing searchable text (be it Azure-extracted or not) within an image-based PDF page was not replaced with the new Azure text.
FIX#1264: ORGANIZER: Some pages with a very short width compared to its height or vice versa which were rotated in the Organizer were dramatically downscaled when passing through Convert to Multipage TIF, Convert to Searchable PDF, Convert to Black & White, Scale Page(s), Split Booklets…
FIX #1221: CONVERT TO IMAGE PDF – HELP: Convert to Image PDF setup pointed to the wrong Help Page.
FIX #1226: LICENSING: We did not check the max length when a user entered his license code and info. This could cause errors when the user entered more characters than allowed. We now enforce following limitations:
Serial: 39 characters max
Company: 50 characters max
Name: 50 characters max
Email: 50 characters max
FIX #1228: TEST – HTML ESCAPE CHARACTERS IN TEST RESULTS: Test result boxes were not using HTML escape characters. This sometimes resulted in truncated text.
FIX #1234: TASKS: We now retry if the MetaServer database with a JSON file sync times out.
FIX #1249: TASKS: We support 2-level JSON structures with Nodes and Sub-Nodes. Also when a mapped Node is missing the Node is considered to be blank.
FIX #1209: EXTRACT BARCODE – QR CODE READING: If you did not replace TABs in the QR value, the Set Field Value rule generated an error: Object reference not set to an instance of an object.
FIX #1261: FIND – DATABASE LOOKUP: With Search Method “Is equal to” the last record was not returned. With “Starts with” and “Contains” it worked correctly.
FIX #1301: OPERATOR CLIENT – TRANSLATIONS: We added the Czech translation for the Bookmark menu in the Validation screen: “Záložky”
FIX #1272: DOCUMENT DIMENSION VARIABLES: Using { Document Page Width } or { Document Page Height } in a Set Field Value rule, generated a run time error.
NOTE: The dimensions of a documents are those of the first page of a document.