060 MetaServer Separate Document / Process Page
– You can automatically separate documents based on unique words or barcodes found on the first or last page of the document.
– You can also use separator sheets during scanning to indicate the beginning of each document. Separator sheets can be useful if you don’t have any free space on your document for a barcode or there aren’t any unique values on the first or last page.
– You can also separate every n page(s). In other words, if you separate every “1” page, a PDF file of 20 pages will be converted to 20 individual PDF files with each 1 page. This is useful when you want to scan a stack of, for example, single page delivery notes.
– To auto-delete certain pages, you can automatically delete documents using rules. For example, delete a page if no text is found using OCR
– To auto-rotate pages, you can automatically correct the orientation of your pages based on the text orientation on each page or based on the orientation of a barcode.
If you want more detailed instructions on how to set up auto-rotation and deletion of blank pages, please refer to the following online guide.
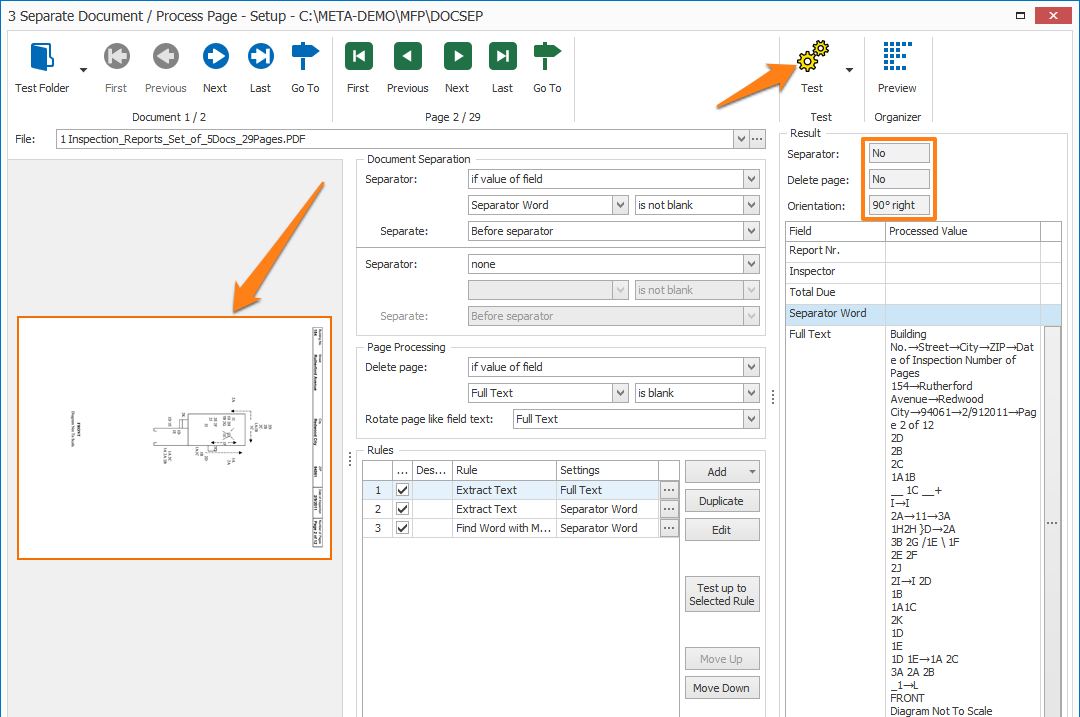
You can test your document separation and page processing configuration instantly using a sample document.
The Separate Document / Process Page action is also sometimes combined with the Organize action to double-check the result of the Separate Document / Process Page action or to manually adjust the documents (e.g. moving pages around, etc.).
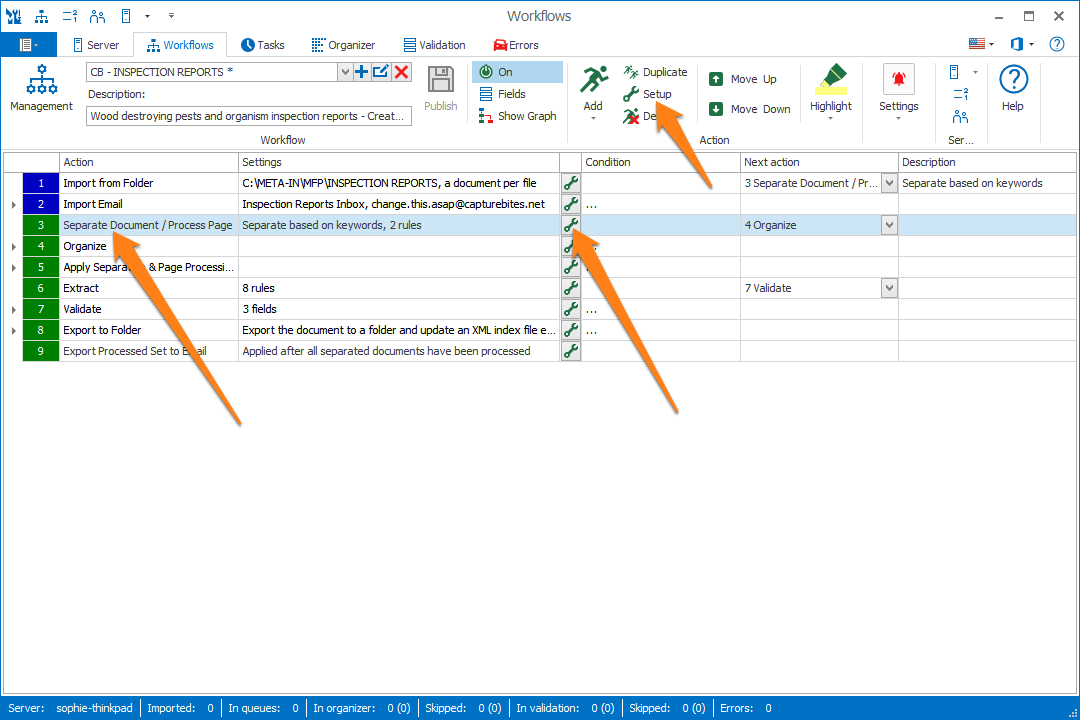
In our example, we will make use of the “CB – INSPECTION REPORTS” workflow. This workflow is automatically installed with CaptureBites MetaServer.






NOTE: By default, an Apply Separation & Page Processing action is added after your Separate Document / Process Page action. The same applies to the Organize action.
This action will ultimately apply the separation of your document. Before this action, your document will only be bookmarked based on your separation points.
If you only want to bookmark your document and apply the page processing (e.g. rotating, deleting, rearranging pages, etc.), you can replace the Apply Separation & Page Processing with an Apply Page Processing Only action.
For more detailed information about this action, please refer to the Apply Separation & Page Processing or Apply Page Processing Only help page.
TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to zoom in.
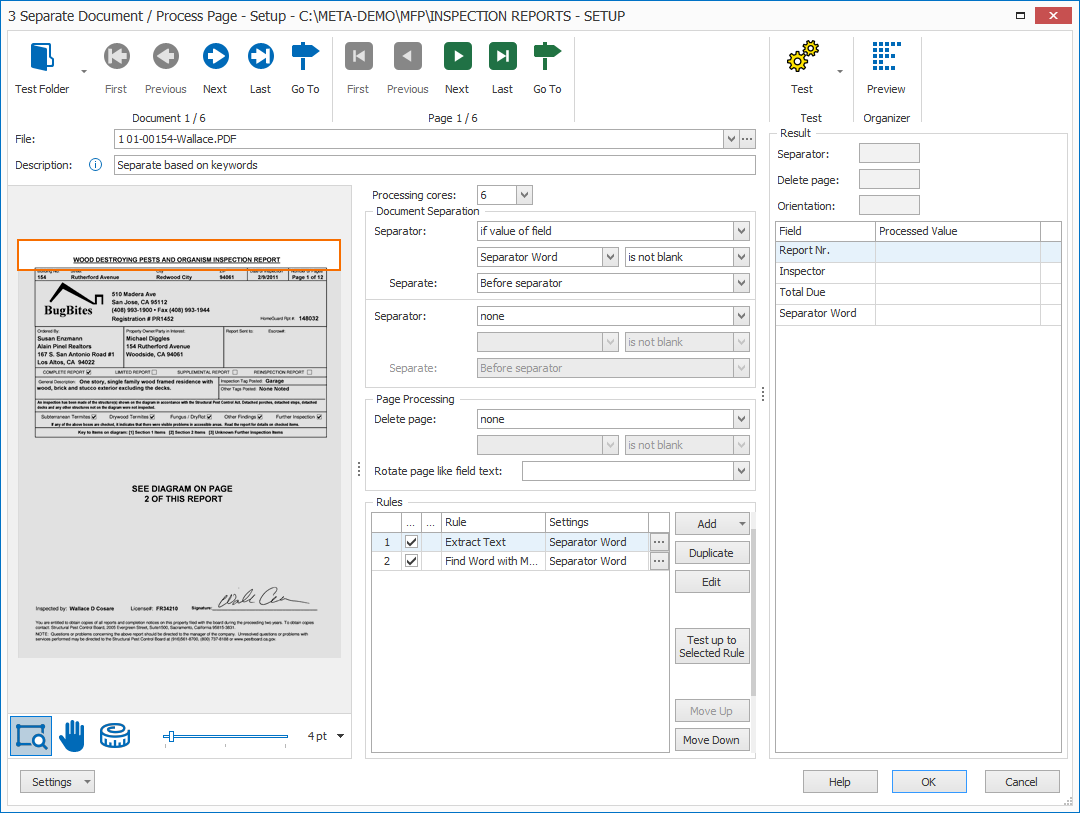
The middle panel shows your Extract rules. You can define as many rules as required.


MetaServer provides the option to support additional cores to speed up extraction.


Below you can find an estimation on the increase of the extraction speed / page:
| 300 DPI A4 / LETTER SIZE | 6 CORES / 12 LOGICAL PROCESSORS |
| Processing Time per Image in Seconds | |
| EXTRACTION ONLY | |
| 6 PROCESSING CORES | 0,55 |
| NO EXTRA PROCESSING CORES | 4,00 |
If you still need to decide your hardware and / or you’re not sure how many extra cores would be best for your particular solution, don’t hesitate to contact us.
If you’ve applied for a trial of MetaServer, we have included support up to 3 additional cores for you to try out.

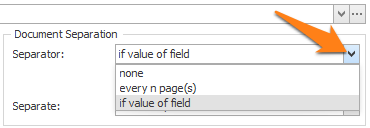
The “is not blank” option is used in combination with a set of rules to find unique keywords on the first or last page of each document and load them in a field. If that field is not blank, it means one of the keywords is present and the page can be considered as a separator.
The “if field value changes” option is useful when the separator value appears on every page of the document. For example, a barcode holding the report number appears on every page of each report, but its value changes when a new report starts.
To disable Document Separation, select none.
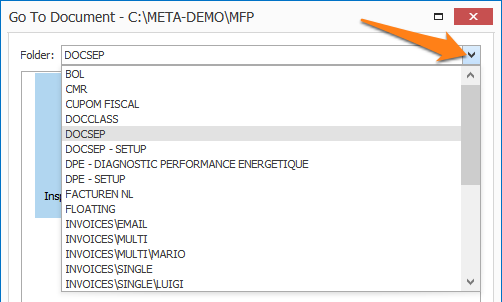
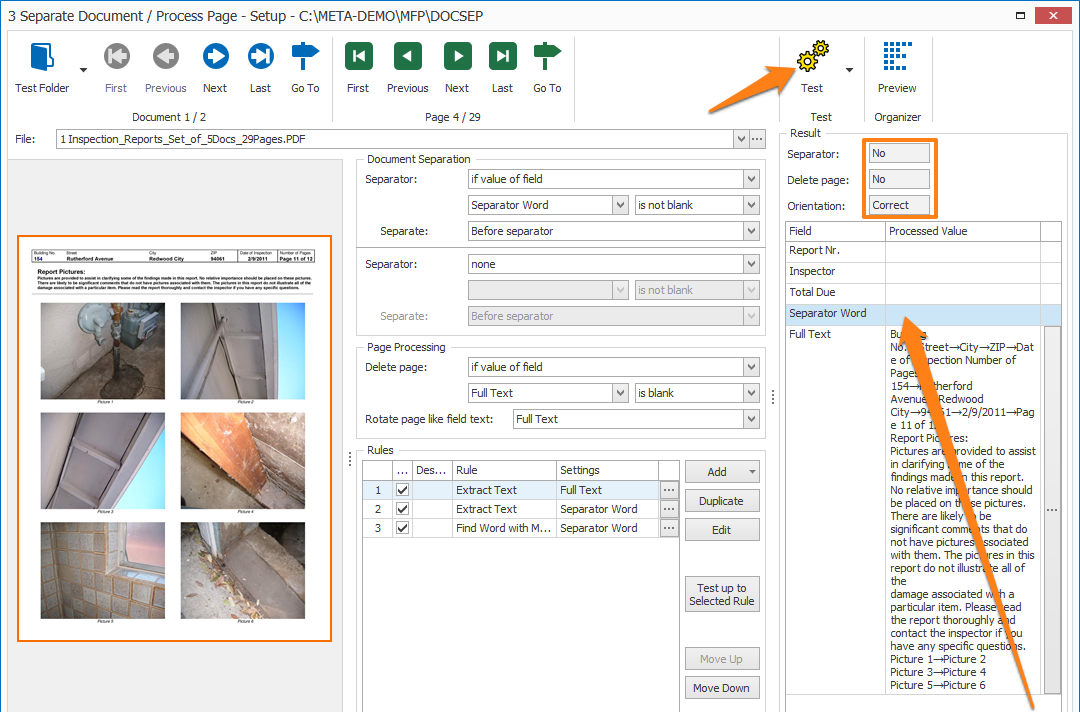
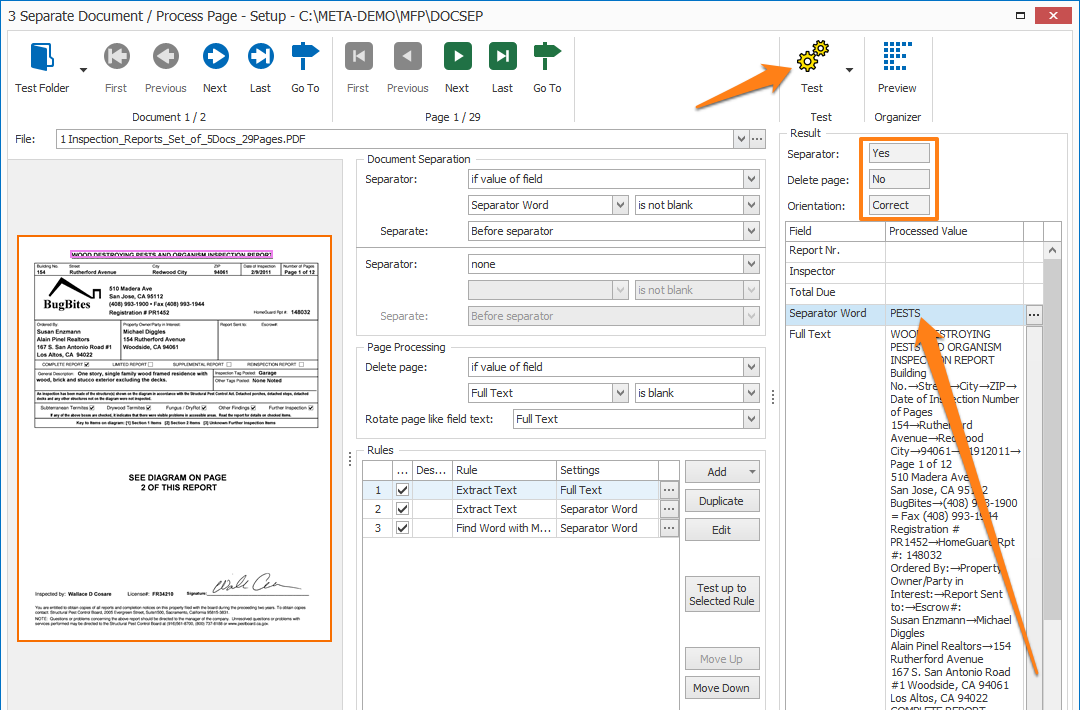
In our example, we only want to separate when we find the big title on top of the page. So, we created a field “Separator Word” and we will separate our documents when the field value is not blank.
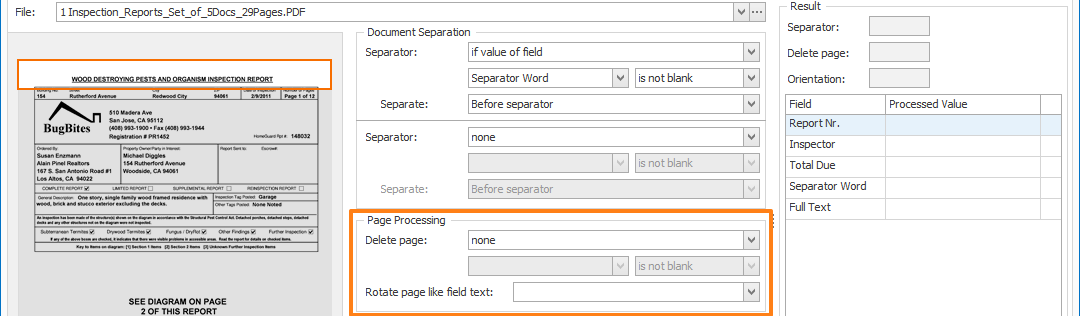
Select separator if you want to delete the page holding the separator value.
For example, you can have landscape-oriented page in a document.


In other words, with a Find Word with Mask / Words rule where you only keep 2-character words or longer, blank pages with noise will also return as blank and will also be deleted.
To speed up the deletion process, you can first extract a small zone of text where you expect some text on most of the pages. But, when that Extract Text rule returns nothing, you are not sure yet if the page is completely blank. So, in that case, you would need to extract the full page. You can do this by adding a second Extract Text rule for the full page and applying the following condition: Apply if field value is blank.
For full, detailed instructions on how to achieve this for auto-rotation and deletion of blank pages, please refer to the following online guide.
Often, the field to detect the text orientation can be the same field as you use to detect the presence of text to delete the page or not.
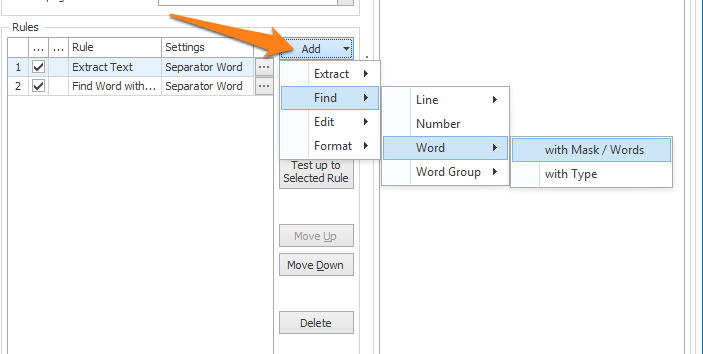
The rules are executed in the sequence of the rules list. Therefore, the order of the rules in the list influences the result.
– Considered a separator, yes or no
– Going to be deleted, yes or no
– Going to be rotated. When enabled, the detected orientation of the page is displayed as 90° right, 90° left, 180° or Correct.

01 – Format: You can use one of the Format options to switch the text to another case. In uppercase, it is easier to detect OCR errors like l versus I (in uppercase, that would be L versus I).
For a more in-depth example, please refer to the following help page.
02 – Show info: by default, this option is enabled. It shows the data type, confidence level and font-size of each word group of the result value.
For example: (Printed 85% 10pt) = The machine printed word group was extracted with a confidence level of 85% and has a 10pt font size.
There are a total of 6 possible data types:
1) Printed = machine written data extracted with OCR.
2) Handwritten = handwritten data extracted with Azure Computer Vision ICR using the Extract Text (Azure Computer Vision) rule.
3) PDF text = text directly extracted from the text layer of an electronic PDF or a Searchable PDF.
4) Barcode = barcoded data extracted using the Extract Barcode rule.
5) Mark = data originating from a check box extracted with the Mark Detection rule.
6) Set value = data that was populated with a Set field value rule to set the current date or time or something similar.
TIP: If you need to design a document and you are not sure what the ideal font type is for OCR processing to avoid these kind of OCR errors, have a look here.

You can also see the total number of documents generated with your rules in the right corner of the status bar.

TIP: you can copy the current settings and paste them in another setup window of the same type. Do this by pressing the Settings button in the bottom left of the Setup window and by selecting Copy. Then open another setup window of the same type and select Paste.

