MetaServer > Version History
CaptureBites MetaServer Version History
You can always download the latest version of MetaServer including Operator, Admin clients and sample workflows on the MetaServer Product Page. If you are looking for base installers without any sample workflows, please refer to our download page.
IMPORTANT: Before refreshing or updating your MetaServer, please pause your MetaServer first. You can do this in your Admin Client, under the Server tab. As soon as all your action queues are "yellow" (= paused), you can perform your refresh or update.
This will ensure that no documents in your current queue become corrupted during your refresh or update.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3, it is possible that a Computer ID mismatch can occur.
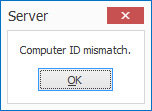
On most systems, the update will not cause any problems. However, occasionally, on some systems this may cause a Computer ID mismatch after upgrading. To fix this issue, please refer to the Computer ID Mismatch troubleshoot page.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1, a pop-up window will ask you to request a serial number. If you haven't received a serial number already, please press the "Request a Serial Number" button and fill out the form. We will send you your serial number as soon as possible.
Please also note that old MetaServer activation codes (e.g. "K-123F0-12345-123B4-CD12B-C0D12-E1EB2") are not compatible with this version and future releases of MetaServer. You can apply for a replacement serial number through our online request form.
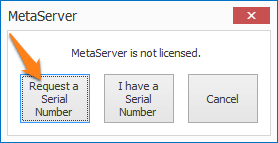
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23, it is required to republish existing workflows. Select each of your workflows, make a small change, like adding and removing a space to the workflow description, and publish the workflow. If there are documents already imported in the workflow, then you do not have to apply the changes to these documents.
Version 3.1(19) | 2022-05-20
NEW #851: ALL EMAIL RELATED FUNCTIONS NOW SUPPORT GMAIL OAUTH20: We now support Google Gmail’s Oauth20 authentication in Import Email, Export to Email, Forward Email and Error Emails.
By the end of May 2022, Google will no longer make it possible to log in through basic authentication with unsecure applications. MetaServer is now officially certified by Google and you can now login through OAuth20.
To switch to OAuth20 in the Import Email action, just select Gmail instead of IMAP and sign in. In the Export to Email, Forward Email and Error Emails Setup, just select Gmail as “Server type” instead of SMTP and sign in.
OAuth2 Gmail tokens are saved in “C:CaptureBitesMsDataQueuesGmail”.

NEW #1189: IMPORT / EXPORT / FORWARD EMAIL – SUPPORT OFFICE 365 OAUTH20: We now support Office 365 OAuth20 authentication in Import Email, Export to Email, Forward Email, Error Email and Export Processed Set.
On October1st, 2022, Microsoft will disable basic authentication for Exchange Online and you will need to switch to the new OAuth20 authentication.
To switch to OAuth20 in the Import Email action, just select “Office 365” instead of IMAP and sign in.
In the Export to Email, Forward Email and Error Email Setup, just select Office 365 as “Server type” instead of SMTP and sign in.

OAuth2 tokens are saved in “C:CaptureBitesMsDataQueuesOffice”. The “Refresh Tokens” queue reads the info of all users in .”..Office” every time MetaServer is started. After that, it is refreshed every month. It will refresh the access tokens that have expired.
NEW #1064: IMPORT EMAIL: You can now select another IMAP or GMAIL folder than the INBOX to import emails from. We tested it with Exchange 365, Gmail, Webmail (Telenet) and OVH mail.
NEW #1155: IMPORT EMAIL – ZIP SUPPORT: You can now also import Zip attachments. Automatically, any Zips are unzipped and any PDFs, TIFs, JPGs or PNGs contained in the Zip are imported and each is considered as an attachment. Also, Zip in Zip is supported.
NEW #1171: TASKS – SYNC METASERVER DATABASE: We can now synchronize a MetaServer database with a JSON file retrieved with a web call.
NEW #1153: EXPORT TO DOCUWARE – DYNAMIC CABINET / TRY SWITCHING: You can now set the Cabinet / Tray using a MetaServer index field. This way, you can automatically store a document in a specific tray or cabinet depending on its content.
NEW #1185: EXPORT TO DOCUWARE – PRE-INDEXING: We now make it possible to pre-index documents that are exported to a document tray.
Previously, it was only possible to index documents that were directly exported to a cabinet. With the pre-index feature, the DocuWare user can now first add some additional data next to the pre-indexed data before moving it permanently to a Cabinet.
ENHANCEMENT #1185: EXPORT TO DOCUWARE – HIDE SYSTEM FIELDS: Only DocuWare database fields are now displayed in the mapping list.
Previously, all system fields, which could not be updated, were always listed. This made the mapping list needlessly long.
ENHANCEMENT #1054: EMAIL ALERT: We moved the actual error to the beginning of the email text to make it easier to find.
Before, the error text was at the end of the email text.
ENHANCEMENT #1188: IMPORT FROM FOLDER – IGNORE 0 BYTES FILES: We had a case where the customer used a device that initially created a 0 bytes PDF in the watched folder. It was only updated up to 30 minutes later with the final PDF content, depending on the number of pages.
We had to set the delay to 30 minutes, but as soon as the file was complete, it took another 30 minutes to import it.
With the enhancement to ignore any 0 bytes files, the import delay will only start as soon as the file > 0 bytes. So, now the import delay can be set to a short value, like 30 seconds.
ENHANCEMENT #1174: METASERVER AUTO-DISCOVERY: We adjusted the message that shows after canceling the auto-discovery process and added a HELP button linking to the How to connect multiple clients to a central MetaServer online help page.

ENHANCEMENT #1181: EXTRACT TEST (AZURE COMPUTER VISION) – SEARCHABLE PDF: When you extract an Azure Searchable text layer with the Use searchable text layer if present option, the default tab length of 60 results in every word becoming an individual word group. We changed the default value to 200. This returns normal word groups when the Azure Searchable Text Layer is extracted.
ENHANCEMENT #1195: ORGANIZE – AUTO-DISPLAY FIRST PAGE: When pressing OK in Organizer and the next document was loaded nothing was displayed in the large page viewer. The user also had to click on the first page to load it.
FIX #1192 and #1201: IMPORT – TIF IMAGES WITH SPECIFIC BOOK SCANNERS: Some uncompressed TIF images scanned with specific book scanners failed when converting to JPG. This resulted in green images in Organizer and Validation or caused Import errors, etc.
By making a new copy of the image, the conversion succeeds. We now make a new copy when saving a JPG image fails.
FIX #1180: EXTRACT TEXT (AZURE COMPUTER VISION) – DESKEW AND AUTO-ROTATE: From now on, the Use searchable text layer if present option wins over the VRS lite options when a searchable text layer is detected.
So, if the Use searchable text layer if present option is enabled and a searchable text layer is available, the VRS Lite rotate and deskew options are ignored.
Only when there is no searchable text layer, the VRS Lite rotate and deskew options and OCR are applied.
This should be the case in the all instances of the Extract Text (Azure Computer Vision) and Extract Text rules:
FIX #1179: INCORRECT ORIENTATION OF SOME ELECTRONIC PDF’S TEXT: If the PDF featured an orientation tag, then the PDF was displayed correctly but the text was not.
FIX #1177: FIND / DATABASE LOOKUP: The “Keep unique matches” option returned erratic results.
FIX #1161: IMPORT EMAIL: Since version 3.1.17, an error occurred when importing an email without attachments or if it only contained invalid attachments (like *.xls or *.doc). The archiving of the rejected email failed with an error:
“Error: Index was outside the bounds of the array.”
FIX #1144: IMPORT (MSG FROM DISK) AND FORWARD EMAIL: MSG or EML emails imported from disk could not be forwarded.
FIX #1189: VALIDATE AND ORGANIZE – REJECT REASONS: If multiple actions had a different number of reject reasons, the Reject button sometimes showed a blank Reject Reason.
FIX #175: VALIDATE AND ORGANIZE – REJECT REASONS: The Reject Reason did not change when consecutive organizer or validation actions changed it.
FIX #1191: EXTRACT TEXT (AZURE COMPUTER VISION): This is about the erratic error: “Cannot access the file…” when using the Test function in the Extract Text (Azure Computer Vision) setup. This is typically caused by Anti Virus software locking files for a short instance. We now retry SaveBytes and LoadBytes when they fail to fix this.
Version 3.1(18) | 2022-04-01
NEW #1149: EXTRACT TEXT (AZURE COMPUTER VISION) – CONVERT PAGES TO SEARCHABLE PDF: the new Convert Pages to Searchable PDF option adds the extracted machine and handwritten text to a searchable text layer in the processed PDF.
If you apply an Extract Text (Azure Computer Vision) rule during a Separate Document / Process Page action with this option enabled, every page of the processed PDF will become searchable.
If you apply an Extract Text (Azure Computer Vision) rule during an Extract action, only the pages specified in the Page(s) range will become searchable. If you leave the Page(s) range empty, all pages will be converted.
You can find more examples and detailed information of this new option in the Extract Text (Azure Computer Vision) help page.
 to searchable PDF")
As a result, you will be able to search handwritten, arabic, cyrillic or low-quality text in your exported PDF:
 to searchable PDF_Example 1")
 to searchable PDF_Example 2")
 to searchable PDF_Example 3")
This high-quality text layer can also be used during Validation with the Select text tool. To do this, please make sure you also enable the “Use searchable text layer if present” option in the Select text tool setup:

NOTE: If you haven’t had the chance to see the results of the Azure Computer Vision engine that MetaServer uses in the Extract Text (Azure Computer Vision) rule, it’s an incredible leap forward in recognition accuracy of both machine-printed and handwritten text in all traditional languages, but also in Cyrillic, Arabic, etc.
You can find more information on our Extract Text (Azure Computer Vision) help page.
NEW #1117: EXTRACT – FIND DB LOOKUP: in previous versions, a DB lookup was done through “Find Word” rules using the “Accept words from database” option. However, this was not the most efficient way to do a DB lookup if you knew the exact lookup value. For example, to look up the supplier name through his “Tax ID”, a slow sequential lookup was performed.
We have now implemented a direct Database Lookup rule. It supports direct MsSQL, ODBC and MetaServer (CSV) databases.

The selected lookup field’s “Value” can be a combination of field values or a fixed value. If you use a SQL or ODBC database, the lookup takes advantage of indexed fields, makes more efficient use of memory and is therefore many times faster than the old DB lookup method.
Just like the Validate Database rule, you can specify if the looked up field should be exactly equal to, start with or contain the specified value.
You can also specify filters. For example, to look up a customer where [country] = FRANCE and where [status] = ACTIVE.
If the lookup returns more than one record, you can specify to keep all matches, the first match, the last match, unique matches or to skip the lookup.
To map other fields with the values from the database, you can make use of the “Field Mapping” tab.
NEW #1157: TASK SCHEDULER – SYNC DATABASE: NEW “HIDE DIGITS AFTER DECIMAL” OPTION: Oracle NUMBER(14) are integers but reported as DECIMAL by ODBC. To avoid that an order number like 123456 is returned as 123456.00, we have added a new option to hide the decimals.
This can also be useful if ID numbers are stored as a NUMERIC or DECIMAL data type in MsSQL.
FIX #1162: METADATA FIELD FIX – DOCUMENT PAGE NUMBER: { Document Page Number } was not always correctly resolved during runtime. When combined with multiple lines in a field, which was then used in a CSV, the { Document Page Number } was always equal to 1, even if the line came from another page than 1.
FIX #1170: DB LOOKUP – LOOKUP IN TWO LARGE DATABASES CAUSED AN OUT OF MEMORY ERROR: The main issue is that no error was reported and it was as if the lookup just didn’t find the lookup value while, in reality, an “Out of Memory” error occurred on the server.
As an indication, the total size of all MetaServer CSV databases loaded in memory should not exceed 250 MB. When this limit is exceeded, MetaServer now reports a meaningful error.
FIX #1159: VRS LITE – ERRATIC ERROR: The erratic error “VrsEngine: missing process one PDF page with VRS job result file” is fixed.
FIX #1063: METASERVER AUTO-DISCOVERY – FAILS AND CLOSES THE CLIENT: On some systems (less than 1% of our installed base), when you first opened the Operator or Admin client, the auto-discovery process failed and unexpectedly closed the client.
This was caused by security restrictions on the network preventing the auto-discovery to work. We now show the Windows error “A socket operation was attempted to an unreachable network” instead of a complete closure of the client.
In this rare case, you just need to press “Continue”, close the Auto-Discovery Box and manually set the connection between the client and the server. You can find more detailed instructions on our dedicated, online How-To page.

FIX #1175: VALIDATE DATABASE LOOKUP – ORACLE DB: Oracle defaulted to fetch (all records in memory) because of an SQL syntax error. This is fixed by merging the “WHERE ROWNUM” clause with the first “WHERE” clause:
SELECT [PatientName]
FROM [Patient_Records] WHERE (UPPER('1')='0'
AND (ROWNUM <= 1))
ORDER BY [Patient_Records].[PatientName]
Version 3.1(17) | 2022-03-11
NEW #1093: MARK DETECTION (OMR) – IMPROVED HANDLING OF MASTER: the document used to draw the anchor points and check marks, was implicitly considered as the Master document. If you, by accident, changed the settings on another document, this could break all settings of the Mark Detection rule.
Following changes makes accidental changes on a non-master document unlikely:
1) Initial Master
When you open a Mark Detection rule without a Master, the current document is automatically selected as master and displayed in a text box next to the Page.
2) Changing the Master
Next to the text box displaying the master document, there is a menu with a “Set current file as master” option. You just load the document you want to use as Master in the viewer and select “Set current file as master”.
3) Opening settings with a Non-Master document
When you open the setup of a Mark Detection Rule and the Master is not loaded, you get a message:

4) Trying to OK changes on a Non-Master
When you press OK when the Master is not loaded, a warning message pops up:

5) Loading the Master
Next to the text box displaying the master document, there is a menu with a “Load master” option. When the Master is not loaded, you can use this to instantly load the master document and start making changes.

ENHANCEMENT #1010: MARK DETECTION (OMR) – NEW DETECTION METHOD “PEAK”: There are now 3 methods to detect the blackest check box in the Mark Detection rule:
1) Count (default): We count the black pixels in the selection. If it is higher than the set pixel threshold, the mark is considered as checked.
2) Percentage: We calculate the percentage of black pixels as compared to the total number of pixels (black + white) in the selection. If the percentage is higher than the % threshold, the mark is considered as checked.
3) Peak: This new method is useful when scan quality varies a lot. This causes the threshold to vary a lot because the number of black pixels in an unchecked box (the reference) varies a lot (see examples below). The unchecked boxes will have a very different number of black pixels depending of the scan being a bit fuzzy, good quality or dithered.
Good quality, resulting in an empty box with a normal level of black pixels:

Fuzzy, typically resulting in an empty box with a higher level of black pixels:

Dithered, typically resulting in an empty box with a lower level of black pixels:

The peak method only works with a minimum of two check boxes. This is because the check box with the least black pixels will be set as the reference empty check box at 0% black level.
The other check boxes will be compared with the reference, resulting in a percentage of black pixels in comparison to the reference. The boxes with a percentage higher than the minimum % threshold and lower than the maximum % threshold are considered as black.
NEW #1068: MARK DETECTION (OMR) – SCALING FEATURE: The Scale page(s) feature is particularly interesting when you receive forms from different sources not respecting the scale of the original form, the master document.
This often happens when the form is distributed as a PDF which is printed. If the user prints with the “fit to margins’ feature the original will be slightly zoomed out. Even worse if the form is first printed and then photographed with a smart phone using a scan app. Depending on the distance of the lens and the margins, the distances between the objects can be completely different as compared to the master document.
The Scale Page(s) feature uses one or more sentences (longer sentences are better) on the Master document as reference points. If a form returns the reference sentence smaller, then the check box selections will be scaled up proportionally and vice versa.
Before scaling and registration:

After scaling and registration, the check boxes are perfectly detected:

NEW #1101: MARK DETECTION (OMR) – MULTIPLE MARKS / KEEP BLACKEST VALUE: This new mark detection method keeps the mark with the blackest value. That means:
1) Count mode: The blackest mark is the mark with highest black pixel count, which is also higher than the min. pixel count.
2) Percentage mode: The blackest mark is the mark with the highest percentage, which is also higher than the set percentage threshold.
3) Peak mode: The blackest mark is the mark with the highest percentage, which is higher than the min. percentage and below the max. percentage.
NEW #1038: EXPORT TO SHAREPOINT – DYNAMIC CONTENT TYPE SWITCHING: You can now dynamically switch content types using a MetaServer field.
NOTE: Column mapping is possible, but only for columns with a common id between the content types.
You just select any of the possible content types, and you use that one for mapping. After that, press the “Setup” button next to the content type and select the field containing the content type. The value in the field must be identical to an existing content type name in SharePoint.
During export, the field’s value will be used to switch content type dynamically. Only SharePoint columns with ids common between all content types can be mapped.
NEW #1062: EXPORT TO FOLDER – FILE INDEX: We added a new File type “JSON”. If you select JSON values contained in index fields will escape the special JSON characters ” and \.
– Double quote is replaced with \”
– Backslash is replaced with \\
– Line Separator with \r\n
NEW #1061: FIELD LABEL VARIABLES: We added a new variable group called “Field Labels” which is useful when creating an XML, CSV or JSON File Index to define the header or object names. When you change the field label in your workflow’s Fields setup, the label automatically changes in the file index as well.
For example: The label corresponding with a field value contained in { Field, DOCUMENT TYPE } is represented by { Field Label, DOCUMENT TYPE }.
NEW #1074: FIELD CONFIDENCE LEVELS: We added a new variable group called “Field confidence levels” which is useful when creating an XML, CSV or JSON File Index to include the confidence of each field. The confidence level is a percentage and can have a value between 0 and 100.
For example: The confidence level corresponding with a field value contained in { Field, FIRST NAME } is represented by { Field Confidence, FIRST NAME }.
NEW #1066: EXPORT TO FOLDER – FILE INDEX SETUP: We added a new option to the variable selection menu called “JSON” to insert JSON formatted fields.
You set the cursor where you want to insert the fields and select the “JSON” option in the selection menu:

This opens a window with all available fields and check boxes in front of them. Just select the fields that you want to insert in JSON format. There is also an option to prefix the fields with a number of tabs and include the confidence level for each field. By default, two tabs are inserted in front of the JSON index entries.

As soon as you have selected the desired fields and options and press OK, All corresponding field label and field value pairs are inserted with the selected number of tabs in front of them and with double quotes, double colon and trailing commas as required by the JSON format like this:
“{ Field Label, Vendor }”: “{ Field, Vendor }”,
“{ Field Label, Invoice Nr. }”: “{ Field, Invoice Nr. }”,
“{ Field Label, Invoice Date }”: “{ Field, Invoice Date }”,
“{ Field Label, Due Date }”: “{ Field, Due Date }”,
“{ Field Label, Payment Term (days) }”: “{ Field, Payment Term (days) }”,
“{ Field Label, Total Amount after Tax }”: “{ Field, Total Amount after Tax }”,
“{ Field Label, Total Amount before Tax }”: “{ Field, Total Amount before Tax }”,
“{ Field Label, Tax Amount }”: “{ Field, Tax Amount }”
NEW #1087: EXPORT TO FOLDER – FILE INDEX SETUP: We now allow to use Tabs in the text boxes to make it easier to visually format XML and JSON files.
NEW #1077: EXTRACT – NEW RESULT LIST SETUP: It is now possible to show/hide specific fields in the result list of each Extract action. This is very useful when you have defined a lot of fields.


Show all fields:

Only show selected fields from list:

NEW #1110: VALIDATE – DATABASE LOOKUP: We added a new “Hide digits after decimal” option. Oracle NUMBER(14) are integers but reported as DECIMAL by ODBC. To avoid that, for example, an order number like 123456 is returned as 123456.00, we have added an option to hide the decimals. This can also be useful if ID numbers are stored as a NUMERIC or DECIMAL data type in MsSQL.
Also, from now on, thousand separators are never displayed in looked up decimal values, regardless of the option’s setting.
NEW #1091: SERVER MONITORING FUNCTION: When you enable this new Server Monitoring option, MetaServer updates a “metaserver-monitoring.json” file on disk every minute.
The interval, the folder and file name can be adjusted. The monitor file contains all counters as displayed in the Counters pop-up and other server level data like SystemUpTime, MetaServerUpTime, MemoryInUse, etc.
You can use this for server monitoring systems such as Centreon.


For example, the result will be:
{
"Date": "2022-02-11T16:51:00.0139559+01:00",
"SystemUpTime": "1.07:49:10.6250000",
"MetaServerUpTime": "00:10:18.0463425",
"MemoryInUse": 104263680,
"PeakMemoryUsed": 132358144,
"DocumentsImported": 2,
"DocumentsInQueues": 4,
"Actions": {
"Apply Page Processing": 0,
"Apply Separation & Page Processing": 0,
"Archive Email": 0,
"Check Validity": 0,
"Classify": 0,
"Convert Email to PDF": 0,
"Convert Email Body to PDF": 0,
"Convert to Black and White": 0,
...
"Preprocess Document": 0,
"Run Programs": 0,
"Select": 0,
"Separate Document / Process Page": 0,
"Set PDF Properties": 0
"Validate": 2,
"Validate Skipped": 1
}
}NEW #1056: WORKFLOWS TAB – DIAGNOSTIC LOG MENU: In the workflows tab, we have introduced a new menu-button called Log. Currently, you can enable the “Email communication” log and / or the “Kofax VRS” log.
When new logs are introduced, they will be added to the Log menu.

NEW #1089: IMPORT FROM FOLDER – IMPORT x SECONDS AFTER WRITE TIME and IMPORT x SECONDS AFTER ACCESS TIME : When a file is created in parts, like when an FTP server is writing in a folder, the write time is continuously updated. The write time is the most accurate time stamp to decide to start the import of a file if a device or an FTP server writes directly in the watched folder and works in the majority of the cases. This is also the default.
The last file’s access time is updated when you copy a file from one folder to another. So this is a good option when copying existing files in the watched folder because the write time is not updated by windows when you just copy a file into the watched folder.

NEW #1071: NEW VARIABLE – DOCUMENT PDF COMPLIANCE: To set the { Document PDF Compliance } variable you need to put the PDF through a licensed Convert to PDF/A action and enable the new “Detect PDF compliance” option in that action. With this option enabled, the Convert to PDF/A action does not change the PDF at all and only detects its compliance level.
The compliance level can be one of the following:
PDF/A-1a
PDF/A-1b
PDF/A-2a
PDF/A-2b
PDF/A-2u
PDF/A-3a
PDF/A-3b
PDF/A-3u
PDF (if not PDF/A)

NEW #995: EXPORT TO FOLDER – NEW VARIABLE: You can find these new variables in the Export/File menu in the file index setup.
{ Export File SHA256 }: contains the SHA-256 hash key of the exported file and can be included in the file index. This hash key can be checked by the receiving system to assure that the file is intact.
{ Export File Content Base64 }: contains the complete exported document as a Base 64 binary image data stream and can also be included in the file index. You can, for example, use this in an HTML file output to display the document as an HTML page.
NEW #551: ORGANIZER / VALIDATE – OPEN LIST: All “Open List” windows now remember all set filters and the sort sequence.
There is also a new “System Columns” button where you can show or hide each of the fixed system columns: “Workflow”, “Date Created” and “Reserved by”. This setting is also remembered.
ENHANCEMENT #1069: EXPORT PROCESSED SET – INDEX FILE: We renamed the “Export Processed Set to Email” action to Export Processed Set and made it possible, besides sending an email, to also create a file index.
This makes it possible to create a trigger file in the export folder of the separated documents of a set. Only when all separated documents are finished, the trigger file is written and an external process can use the trigger to post-process the documents.
Version 3.1(16) | 2021-11-09
NEW #1005: EXTENDED INFORMATION PER WORD GROUP: Throughout the life of a document, extended information is now visible per word group:
For example: (Printed 85% 10pt) = The machine printed word group was extracted with a confidence level of 85% and has a 10pt font size.
There are a total of 6 possible data types:
1) Printed = machine written data extracted with OCR.
2) Handwritten = handwritten data extracted with Azure Computer Vision ICR using the Extract Text (Azure Computer Vision) rule.
3) PDF text = text directly extracted from the text layer of an electronic PDF or a Searchable PDF.
4) Barcode = barcoded data extracted using the Extract Barcode rule.
5) Mark = data originating from a check box extracted with the Mark Detection rule.
6) Set value = data that was populated with a Set field value rule to set the current date or time or something similar.
By default, the data type and additional info is shown and can be hidden with the “Show info” option in the result panel of:
Extract Text
Extract Text (Azure Computer Vision)
Extract Barcode
Separate Document / Process Page(s)

NEW #994: EXTRACT TEXT (AZURE COMPUTER VISION) – EXPOSE PREVIEW READ MODELS: The Azure Computer Vision OCR engine improves over time and Microsoft releases new Read Models through, what they call, Preview Models.

New read models are introduced by Microsoft to improve read rate or add new languages. For example, the 2021-09-30-preview model added support for French handwriting (accents), Arabic OCR, Nepali OCR and Cyrillic OCR for languages like Russian.
With this release, you can now load the General Available Model (GA Model) or load a preview model. Release info and preview model names are documented here: https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/cognitive-services/Computer-vision/whats-new.md
Currently there are only two models available: 2021-04-12 (current GA model) and the 2021-09-30-preview model.
NEW #979: FIND SELECTED TEXT RULE: With The Find Selected Text rule you can select a zone on an image and only keep the selected word groups generated with a previous Extract Text, Extract Text (Azure Computer Vision), Extract Barcode or Mark Detection rule.
This is especially useful with the page count based Extract Text (Azure Computer Vision) rule. You read the full page once (= it counts only 1 page read). Next, you can extract zones from the full text result with the Find Selected Text rule without having to rerun the OCR on the zone.
The Find Selected Text rule can also be used to filter already extracted text on font size and minimum confidence.

NEW #982: FIND WORD WITH CONFIDENCE: With the Find Word with Confidence rule, you can select the word with the highest confidence from a range of words.

NEW #968: EXPORT TO WEB SERVER – INPROCESS: We added a new web service connection to export PDF documents to InProces (NL).
Version 3.1(15) | 2021-10-12
NEW #866: EXTRACT TEXT (AZURE COMPUTER VISION): With MetaServer’s Extract Text (Azure Computer Vision) rule, you can extract handwritten and machine-printed information from your imported documents and store it in fields.
This engine is proficient in reading deteriorated images, fuzzy, noisy or deformed or very faint images with a single setting.
It can also read 122 different languages and detects these languages automatically, even in the same text line. Please refer to Azure Computer Vision’s documentation for a complete list of supported languages (“Read” column).

The Azure Computer Vision is licensed as a MetaServer add-on module (product code CB-META-AZCV) in combination with a Microsoft Azure Computer Vision subscription.
The way the Azure Computer Vision engine works, is that you also need to sign up for the Azure service itself. There is a free, 1-year plan where you can test the engine up to 2500 pages per month (F0 Plan). Paid plans are available starting from 1$ per 1000 pages (S1 Plan).
For more examples and information on how to apply for a key, please refer to the online help page.
NEW #965: EXPORT TO DATABASE – EXPORT PDF FILES TO A BLOB FIELD: BLOB (Binary Large Object) fields are also known as “VARBINARY(MAX)” or “IMAGE” fields in MsSQL. In the Field Mapping tab of the Export to Database action, press the dropdown button next to the “Upload image” field and select the BLOB field in which to upload the processed PDF.

BLOB support in MetaServer is more flexible in MetaServer than it is in the Database export connector for Kofax Express. In MetaServer, uploading the processed PDF file in a BLOB field not only works in MsSQL direct mode, but also in ODBC mode and works in both “Always Add Records” and “Update Records” mode.
NEW #881: CONVERT TO PDF/A – SKIP & SEND TO ERROR OPTION: New Convert to PDF/A option to skip conversion if the PDF cannot be converted. By default, PDFs that cannot be converted are still sent to the Errors tab. Now, you can change that and choose to “Skip” the document instead.

The Convert to PDF/A action has two outputs now: “Converted” and “Skipped”:

This way, you can apply different actions for “Skipped” PDFs versus “Converted” PDFs.
For example, skipped PDFs can be converted to Image PDF first using the Convert to Image PDF action (see version history note #976 (below)). After that, you can retry the Convert to PDF/A action once more to convert or sign the skipped PDF after switching to the image PDF format.
NEW #976: CONVERT TO IMAGE PDF: Some electronic PDF files, like PDF XFA, cannot be signed or converted to PDF/A or be extracted from correctly. The Convert to Image PDF action allows you to convert these PDFs to image-only PDF before sending them to the action that does not support the original PDF.
ENHANCEMENT #947: CONVERT TO PDF/A AND SIGNING: We’ve enhanced the “Convert always” Option in combination with the signing option by setting the claimed compliance when the option is disabled. This makes it possible to sign an already PDF/A compliant PDF and keeping its compliance level.
ENHANCEMENT #503: IMPORT ACTIONS – PDF XFA IMPORT OPTION: PDF XFA is a legacy format that is not supported by Adobe anymore and replaced by “ACROFORM”.
For archiving purposes, you still may need to process PDF XFA files but they will cause a lot of problems because of their unsupported, complex format. To avoid these problems, you can enable a new option in the Import from Folder and Import Email action called “Convert PDF XFA to Image PDF”.

This option is enabled by default to avoid Server errors since native PDF XFA is not supported with the following actions:
Set PDF Properties
Convert to Black and White
Convert to Searchable PDF
Convert to Multipage TIF
Convert to PDF/A
Convert to PDF MRC
Convert to JPG
Delete Page(s)
Add External Documents
Split Booklets
Scale Page(s)
All these actions will function correctly if you keep the “Convert PDF XFA to Image PDF” option enabled in the Import action(s). Otherwise, they will trigger an error and move the XFA document to the Errors tab.
Version 3.1(14) | 2021-08-09
NEW #19: IMPORT EMAIL – NEW IMPORT EMAIL OPTIONS RELATED TO ATTACHMENTS AND BODY:
We added new options to specify what and how to import:
Import options:
– 1 document per attachment: this is the default mode and works as currently, you can prepend or append the body by setting the body options (see below).
– Email body: this only imports the body, makes it a PDF and is handled as a regular PDF document in MetaServer. The attachments are ignored.
– Email body and attachments: this merges all attachments in a single PDF and prepends (or appends) the email body. Without the “Apply Separation & Page Processing” action, the Processed PDF format in the Export for Folder action would be the Email body and all its attachments as a single PDF, with an “Apply Separation & Page Processing” action, the email is split in a body and its attachments as separate PDFs.

Body options:
– None: The body is not imported.
– Before attachments: Prepends the body.
– After attachments: Appends the body.

We’ve also moved the Convert Email Body to PDF settings to the Import Email action, next to the Body options. Previously, this was a separate action.
When you select the merged “Email body and attachments PDF” as the import format, the complete email with all its attachments becomes a single bookmarked PDF. The Email with all its attachments can be viewed in the Organizer and a separator marks the start of each attachment and if included, the email body.
For example, below, you see a single email with 11 attachments with the email body appended at the end:

If you view such bookmarked email in Validation, then attachments can be selected from a Bookmark drop-down to easily jump to each attachment or body to help the Operator complete indexing:

Metadata will be applied to all attachments and body after an “Apply Separation and Page Processing” action (see version history note #900).
NEW#913: PDF SIGNATURE: We integrated digital signing using the “myBica sign service” in the Convert to PDF/A action.
The plan is to add other sign services in the future as the need arises. Currently, the “myBica sign service” cannot create linearized signed PDF files. So make sure to disable the “Linearize” option when generating signed PDF/A files.

NEW #892: EXPORT TO FOLDER – FTPS: We added FTPS Implicit and FTPS Explicit to the list of protocols.
ENHANCEMENT #897: IMPORT – WARNING IMAGES: The options “Replace invalid files with red warning image” and “Replace password protected files with orange warning image” will now replace the image with a warning image that includes a QR code with the values “File Not Valid” and “File is Password Protected”.
You can then use the Extract Barcode rule to read those values and let the documents go through a specific flow.
Version 3.1(13) | 2021-05-31
NEW #784: ORGANIZE – CUT / COPY / PASTE: You can now copy / paste or cut / paste pages in the Organizer.

Example Use Case 1: The customer receives complaint forms by registered mail. They want to store each complaint together with the introduction letter and the envelope containing the registered mail number.
Sometimes a single envelope contains multiple complaint forms together with a single introduction letter.
Each complaint should be stored separately including the introduction letter and the registered mail envelope.
Now, the customer can separate the multiple complaints into different documents and copy / paste the intro letter and envelope as many times as there are complaints in the envelope.
Example Use Case 2: You could already drag and drop pages to another position in the Organizer, but this was cumbersome if you wanted to move a page from the beginning to the end of a long document.
Now, you can cut the pages you want to move, navigate to the position where you want to insert the pages and paste them there.
NEW#822: CONVERT TO PDF MRC – CONVERT TEXT BASED PDF: You can now skip text-based PDFs by switching OFF the new Convert Text Based PDF option.

By default, this option is switched OFF. When the option is switched ON, the conversion will only take place if the compressed version of the page is smaller than the original.
FIX #840: RUN PROGRAMS: Workflows / Add / Run Program has been renamed to “Run Programs”.
FIX #807: SEPARATE DOCUMENTS / PROCESS PAGE: Separation failed on some PDFs generated with iText 2.1.7 by 1T3XT.
FIX #850: ORGANIZER: Dutch tooltip for Copy function was still in English.
FIX #857: OmniPage Searchable PDFs were detected as Text based PDFs. This is now fixed for all MetaServer functions.
FIX #738: IMPORT EMAIL (Import MSG files from Disk Mode): If attachments went through separation, the Export to Folder action showed an error.
FIX #852: METASERVER AUTO-DISCOVERY: MetaServer’s Auto-Discovery generates an error on some systems. This happens after the server is found, when retrieving its name and version number. In this version, when this happens, it waits for 0.5 sec and retries, up to 2 retries = 3 attempts.
If it’s not successful, it shows “Error” as the version number instead of a cryptic error.
Version 3.1(12) | 2021-04-30
NEW #299: RUN PROGRAMS: With the new Run Programs action, you can run one or more windows commands or external programs accepting command line parameters.
We have adjusted our “CB – CHECKS & INVOICES” demo workflow with some examples to demonstrate the Run Programs action. This setup is explained in more detail on the Run Programs online help page.

NEW #759 #831 #832 #833: RESERVE DOCUMENTS FOR AN ACTIVE DIRECTORY USER GROUP: You can now define a specific user group using standard Windows Server Active Directory.
In MetaServer, you can use the Reserve rule to select the user group you want to reserve a document for.
NOTE: This functionality is only available if the Operator Client is inside a domain. It is not available on a standalone PC outside any domain.

Anyone belonging to that user group will be able to validate the document. Using this new capability in combination with the next feature (#796), you can isolate documents perfectly and make it impossible for an operator to access documents that don’t belong to his user group.
NOTE: For performance reasons, we check the groups to which the logged user belongs when the Operator Client is started. If the user groups are changed by the Windows Active Directory Admin, for example, adding a new user to a group, then these changes will be detected after closing and reopening the Operator client.
The user can also can refresh the Groups he belongs to by pressing refresh in the Open Document List.

NEW #796: SERVER SETTINGS – OPTION TO ALLOW OR DISALLOW UNRESERVE: The new client option is called “Unreserve” and is located in the Server tab. By default, it is enabled.
Disabling this option makes it impossible for an operator to change the Reservation status of a document and hides the “Reserve” and “Unreserve” buttons in the Open Document window. The “Hide reserved documents” option also becomes unavailable.
Consequently, reserved documents for other users will also be hidden. This is a good way to hide documents between regions using the same MetaServer.
NEW #755: VALIDATE DATABASE – NEW “CONTAINS” SEARCH METHOD: By default, the validate database lookup searches for fields that start with your lookup value (= “Starts with” search method). You can now change this so a field doesn’t need to start with that value, but can just “contain” that value (= “Contains” search method).
Examle use-case:
Example of records:
Color Square International
Cooperative Associates
International Coach Federation Brussels
M&J Trade
Maxwell International
Ryan International
Treasurer of Antwerp
Sometimes the document shows mistakes in the name. For example, instead of “RYAN International” there will be “BYAN International”.
“Byan” won’t return anything and the operator will want to look at companies containing the word “International”.
With the “Contains” search method, when the operator types “International”, all companies containg the word “International” would be displayed in the lookup list:
Color Square International
International Coach Federation Brussels
Maxwell International
Ryan International
NEW #792: FIND WORD WITH TYPE / VALIDATE – SWISS VAT ID CHECK: The 9th digit in the Swiss VAT ID is actually a check digit which is calculated according to a weighted MOD11 algorithm.
For more details, Swiss VAT ID specs are documented in this document on pages 7-8:
https://www.ech.ch/de/dokument/57be808d-9a03-4e9e-a2c5-65f08ca78e44
This check digit can be used to find the 9 digits in the Swiss VAT ID on an invoice using the Find Word with Type rule.
First, normalize the invoice text to remove any “.” or spaces between the digits of the Swiss VAT ID. Then, run a Find Word with Type rule to find the VAT ID.
The check is also available in the Validate action. When you select it, only valid Swiss VAT IDs will pass in Validation.
NEW#806: FIND WORD WITH TYPE – ADDED BLACK LIST: The Find Word with Type rule is regularly used to locate the supplier’s VAT ID on an invoice. But it often happens that the receiver’s VAT ID is also mentioned.
The Black list feature, like we already had it for our Validate rules, can be used to exclude the receiver’s VAT ID number(s).

NEW #828: CONVERT TO PDF MRC – ADDITIONAL CORES: The Convert to PDF MRC action now supports up to 6 cores. You can find more information about this on the action’s online help page.

ENHANCEMENT #811 #813 #814: EXTRACT BARCODE – UPDATED BARCODE ENGINE: We’ve upgraded to the latest version of the barcode extraction engine version 9.1.1.5 (previous version was 8.1.1.10).
The new version of the engine is more accurate and also features new methods to detect skewed barcodes.
There are now 7 possible settings for the Deskew mode:
Legacy deskew method: This is the old method to detect skewed barcodes. You need to set the maximum skew angle in the “Skew tolerance” setting. Higher skew tolerance is slower performance.
Deskew OFF: Disable skew detection: Fastest performance.
Pre-printed barcodes: The barcodes are pre-printed and not skewed on the page but the whole page can be skewed.
1 barcode label: A barcode label is applied and can be skewed on the page.
3 barcode labels: Multiple barcode labels are applied on a single page and the labels can be skewed at up to 3 different angles.
4 barcode labels: Multiple barcode labels are applied on a single page and the labels can be skewed at up to 4 different angles.
More than 4 barcode labels: Multiple barcode labels are applied on a single page and the labels can be skewed at up to 5 or more different angles.
NOTE: Settings 3 through 7 are gradually doing more effort to find barcodes and consequently will affect detection speed accordingly.

ENHANCEMENT #829: ADMIN CLIENT – TOOLTIPS: We’ve added Tooltips to all the client options in the Server Tab.
Version 3.1(11) | 2021-03-24
NEW #300: CONVERT – SET PDF PROPERTIES: You can use the Set PDF Properties action to password-protect PDFs and set permissions for certain operations.

In the future, we also plan to add the possibility to map MetaServer fields or fixed values with the standard and custom PDF properties and set the way the PDF viewer opens. This new action is always included with the base MetaServer.
For example, an index file defined with the name:
INDEX_{ Export Date, YYYY }-{ Export Date, WW }{ Export File Extension }
..would generate a new index file on a weekly basis with a name like:
INDEX_2021-09.CSV
These are the new variables:
{ Import Date, WW }
{ Import Date, W }
{ Export Date, WW }
{ Export Date, W }
{ Creation Date, WW }
{ Creation Date, W }
{ Current Date, WW }
{ Current Date, W }
WW = Week number (01-53)
W = Week number (1-53)
NEW #696: NEW OPERATOR WORKING TIME VARIABLES: { Operator Working Time } and { Operator Total Working Time }
You can find the new variables in the System -> Operator variables list.
{ Operator Working Time } is the time when an Operator opened a document in an Organize or Validate action. If the operator opens and closes or skips the document in a given Organize or Validate action, only the total open time is counted in that Validate action.
Every new Validate or Organize action in the workflow resets { Operator Working Time } to 00:00:00. This way you can keep very precise statistics how much time each Organize and Validation step takes per document.
{ Operator Total Working Time } is the total time an Operator opened a document in all Organize and Validate actions together.
Example 1: In Validation :
A user opens a document in Validation during 5 seconds, then skips it.
1 hour later, the same or another Operator opens this document from the skipped list and spends another 60 seconds and then presses OK.
{ Operator Working Time } = 00:01:05 (always expressed in hh:mm:ss format)
Every new Validate or Organize action in the workflow resets { Operator Working Time } to 00:00:00
Example 2: In the Organizer and Validation:
User opens a document in the Organizer and keeps it open for 45 seconds, then OKs it.
{ Operator Working Time } = 00:00:45
Same or other user opens the same document 1 hour later in Validation for 90 seconds and OKs it.
{ Operator Working Time } = 00:01:30
{ Operator Total Working Time } = 00:00:45 + 00:01:30 = 00:02:15
ENHANCEMENT #696: RENAMED VALIDATION VARIABLES: We renamed the System -> Validation variables group to System -> Operator because these variables refer to both the Organizer and Validation in the Operator Client.
For example:
{ Validation User Name } -> { Operator User Name }
{ Validation Computer Name } -> { Operator Computer Name }
NEW #664: EXPORT TO WEB SERVER: This is the introduction of a generic connector to export through web services. The first implementation is for Gouw7, a software often used by local governments in the Netherlands.
We plan to further expand this action in a future release.
NEW #441: METASERVER MANAGER: This is a new tool installed in the MetaServer folder on the desktop.

With this support tool you can Start / Restart MetaServer in paused mode or only load a limited number of documents in the queue. This is useful when you want to avoid reprocessing documents if your server is in an unstable mode.

ENHANCEMENT #742, #761, #766, #768, #769, #776: IMPROVED STABILITY FOR BIG WORKLOADS: Improved stability when many documents (> 1000 documents) are in the MetaServer queue.
– The open document list in Organizer and Validation, now shows a counter and cancel button when loading a very large list of documents. Reduced memory use.
– Reduced memory use if many documents are queued for Organize, Validate or Skipped.
– Reduced memory use if many documents are queued for “Apply Separation” by unloading redundant separation data
– Restarting MetaServer with many documents in the queue does not cause out of memory issues anymore
Version 3.1(10) | 2021-01-29
NEW #657 #680 #677: EXPORT PROCESSED SET TO EMAIL: The main use case for the Export Processed Set to Email action is to send an email after all documents of a set have been processed.
IMPORTANT: A set is a range of documents originating from a single PDF that was split in multiple documents using the Separate Document / Process Page action or by using the Organizer.
As soon as your workflow contains a Separate Document / Process Page action and/or Organize action, the Export Processed Set to Email action is automatically added at the end of your workflow. The Export Processed Set to Email action is disabled by default.
NEW #654: WORKFLOWS – MOVE ACTION UP AND DOWN BUTTONS: With the Move Up and Move Down buttons you can move Actions to better organize your workflows.
NOTE: Links between actions stay the same as actions are moved, so don’t forget to change those links if required.

NEW #690: SERVER – CONFIGURABLE DOCUMENT TIMEOUT: A document opened in Organizer or Validation is locked for other users and was automatically closed and unlocked for other users after 30 minutes to avoid documents being stuck in validation when someone went for lunch, for example, and forgot to close a document.
We now made this parameter configurable between 15 and 360 minutes. The setting is called “Document Timeout” and can be found in the Clients group in the Server Settings.

NEW #646: TASK – IMPORT METASERVER DATABASE: With the Import MetaServer Database action, you can import CSV files from any location in the local MetaServer DB folder:
C:\CaptureBites\MsData\DB
This is useful for creating a MetaServer database based on an external CSV generated by another program which places the CSV in an unchangeable / fixed location.
NEW #646: BACKUP METASERVER DATABASE: With the Backup MetaServer Database action, you can create a backup of a local MetaServer database and store it somewhere outside of the MetaServer DB folder.
NEW #658: NEW DIAGNOSTIC INFO: After loading the documents, MetaServer writes some info in:
C:\CaptureBites\MsData\Log\DocumentManager.CBMSLog
This log file shows the amount of memory used by its internal database, the document count and the average document size. The file is overwritten when it already exists.
ENHANCEMENT #661: EXPORT TO EMAIL: EMAIL THROUGH LOTUS NOTES SMTP – HANDLING OF NON-EXISTING RECIPIENT: If you try to email to an non-existing email address, most SMTP servers will handle this gracefully and not return an error to the sending application. Instead, it sends a warning email to the sender informing him that the recipient’s address does not exist.
Lotus Notes SMTP works differently and throws an error to the sending application. We now catch this error and send a warning email to the sender informing him that the recipient’s address does not exist.
Version 3.1(9) | 2020-12-14
NEW #324 #634 #635: VRS AUTO-ROTATE & DESKEW INCLUDED WITH TEXT & BARCODE EXTRACTION: The VRS auto-rotate and deskew functionality is now included with the purchase of the Text Extraction or Barcode Extraction module.
The auto-rotate and deskew correction is not only used to optimize Text, Barcode and OMR extraction but the file is also updated with the corrected result resulting in an improved processed file.
NEW #279: VALIDATE – TEXT: We’ve added “Email Address” to the Type list. The regular expression behind this type is:
/^[-a-z0-9~!$%^&_=+}{‘?]+(.[-a-z0-9~!$%^&=+}{‘?]+)*@([a-z0-9][-a-z0-9_](.[-a-z0-9_]+).[a-z]{2,6}|[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3})(:[0-9]{1,5})?$/i

NEW #651: TASKS – NEW RESTART ACTION QUEUE TASK: We added a new task to Restart Action Queues on a scheduled basis. This task is called “Restart Action Queues”.

Action queues are selected by their type. All actions of the same type are restarted.
A restart consists of:
– pausing, stopping and unloading the threads of the selected queues
– instantiating and starting new threads of the same types
Example use-case:
A customer uses a large number of MetaServer databases.
– A MetaServer database is loaded in memory as soon as you access it for speed reasons.
– Imagine the MetaServer database name changes every day through a dynamic DB name based on index field. Every day, the newly named database will be loaded in memory and the old ones will also stay in memory.
These databases are accumulated over time until you run out of memory or until you restart MetaServer (restarting MetaServer unloads all databases).
Instead of doing this manually, you let a task run every day to unload all the databases automatically and only the databases that are used will be loaded in memory.
ENHANCEMENT #240: TEXT EXTRACTION FROM PDF FORMS (ACROFORM TYPE): The fields of a fillable PDF form (AcroForm Type) were not extracted by MetaServer. We can now directly extract AcroForm fields. AcroForm is the most common fillable PDF form format.
NOTE: The less common XFA forms created with Adobe LiveCycle Designer need to be converted to an image first to extract the field values, you do so by enabling the Apply OCR if PDF contains images option.
NEW #291: EXPORT TO EMAIL – HTML PREVIEW: We’ve added a Preview button to the HTML Tab to show the result of the HTML body in an HTML viewer pop-up.

Previously, you had to test your email body HTML code in an external viewer to check for errors or see the final result. You can now do this directly in the Export to Email setup by using the “Preview” button.
ENHANCEMENT #309: EXPORT TO EMAIL: We added a new HTML preset to insert a grid of 3 x 3 thumbnail pages in the email body to display up to the first 9 pages of the document.
ENHANCEMENT #278: EXPORT TO EMAIL: It is now possible to use an index field in the from and the cc field.
ENHANCEMENT #303: EXPORT TO DOCUWARE: The direct document link generated by the connector that you for example can include in an email message is now shorter. The trailing “&queryInInvariantCulture=False” was not required.
Version 3.1(8) | 2020-11-12
NEW: OPERATOR CLIENT: EXTRA LANGUAGE OPTIONS: you can now toggle between:
1) Czech
2) Dutch
3) English
4) French
5) German
6) Italian
7) Spanish
8) Portuguese
This is also available for the Organizer, Validation and Error tab of the Admin Client.
If you require a translation for an unlisted language, please contact us for a localization kit.
NEW #630: NEW CREATION DOCUMENT DATE AND TIME VARIABLES: The date and time is the when the file was originally created.
Imagine that the MFP created the file on 1-NOV-2020 10:30h. You copy or move the file to the MetaServer’s watched folder 3 days later on 4-NOV-2020 12:00. The Creation Date / Time would, in this case, be 1-NOV-2020 10:30h.
NEW #632: EXPORT TO ALFRESCO: SUPPORT FOR ALFRESCO ASPECTS: The Export to Alfresco action now supports Alfresco Aspects. Aspects are global properties that can be used with any Alfresco document type.
1) Aspects are implemented with CMIS 1.1 and CMIS 1.1 Basic Authentication. The “Aspects” button is disabled with other protocols.
2) Aspects can be selected from a list after clicking the “Aspects” button next to “Content type”.
3) A content type must be selected, multiple aspects may be selected. The index fields list show the fields of the content type and the different aspects.
ENHANCEMENT #436: EXPORT TO EMAIL / EXPORT TO ALFRESCO: Added the possibility to use fields as values to set parameters. These allow you to dynamically change settings to, for example, easily switch between Production system and a Test system.
The following parameters now accept fields:
1) Export to Email:
– User Name
– Password
– From
– Display Name
2) Export to Alfresco:
– Address
– User Name
– Password
NEW: #633: IMPORT FROM FOLDER: SCHEDULED PROCESSING OPTION:
Setup shows up to 3 Start processing times:

MetaServer will start importing all available documents at the defined time(s). When finished, MetaServer will wait until the next defined time to import more documents.
For example, if you want to process all documents scanned so far at 12:00 at noon and at 18:00 (6 PM), then you set Time 1 to 12:00 and Time 2 to 18:00.

If 20 documents are available at 12:00, all 20 documents will be processed. Then, MetaServer will wait until 18:00 (6 PM) before starting to process additional documents that arrived between 12:00 and 18:00 (6 PM).
This feature can be used in a notification workflow to send email notifications to people who received scanned mail by postal services. This is a short description of the logic:
You have to define two workflows:
Workflow 1) The first workflow saves the scanned mail once in the user folders and a second time in the watched folder of the second workflow. So you have to define two Export to Folder actions in your main workflow.
The second export is configured in “overwrite if file exists” mode and exports the scanned mail a second time to the watched folder of workflow 2 which will send the notification emails. If a user has received one or more mailings, there will be one PDF in the watched folder of workflow 2 for that user.
If a user has not received any mail, there will be no PDF in the watched folder of workflow 2.
Workflow 2) The second workflow uses the new “Scheduled processing” option and imports PDF files at 12:00 or another moment in time.
The second workflow does nothing with the PDF, it mainly uses it as a trigger to send a notification email to each user who has received an email. User information and other information can be contained in the file name to pass it to the second workflow and to use it in the notification email.
In short, workflow 2 consists of 3 actions.
Action 1) Import is only done once a day, but you have the flexibility to schedule it up to three times a day at fixed times. You have to delete the imported files to get this notification processing daily.
Action 2) The Extract action is purely there to extract data from the name and subfolder of the imported PDFs (recipient name, recipient email,…) for use in the notification email.
Action 3) Export to Email. You select PDF attachment but you uncheck “Attach files”. The idea is to send an email notification without attachments.
NEW #628: EXPORT TO EMAIL: We added “Request a read receipt” option.
NEW #522: VALIDATE – DATABASE LOOKUP: BLACKLIST VALUES: you are now able to blacklist values in the Validate Database Lookup setup. This list can be made in the Blacklist setup or you can specify a field containing a list (the values need to be separated by a semi-colon).
Version 3.1(7) | 2020-10-20
If you require a translation for an unlisted language, please contact us for a localization kit.
Confirmed languages for next build:
– German
– Italian
– Portuguese
– Spanish

NEW #162: PDF MRC: This new option is now complete and fully implemented. PDF MRC reduces the size of a 300 dpi JPG image with about 90 to 95%.
We also made it possible to compress images using JPEG 2000 (J2K). This results in excellent image quality with a file that is about 70% smaller than a traditional JPG compressed image.
NEW: #522: VALIDATE – TEXT: BLACKLIST VALUES: you are now able to blacklist values in the Validate Text setup.

This list can be made in the Blacklist setup or you can specify a field containing a list (the values need to be separated by a semi-colon).
NEW #530: VALIDATION: STICKY VALUES: When a validation field is specified as “Sticky”, then the last value is saved and presented automatically as the value for the next document.
Common Use-Cases for a Sticky Value:
1) The operator validates all documents of a box. It introduces the box number when he starts validating the first document, then the box number stays the same for all following documents until he changes it when starting the validation for a new box of documents.
2) The operator enters the contract date for a series of a contracts with the same date. He enters the correct date on the first contract and it stays the same on all following contracts until he changes it again.
The sticky value is stored per station, per workflow and per sticky field.
When the operator closes the Operator Client or Admin client, and opens it again, the last-used value is presented again in the sticky fields.
NEW #532: VALIDATE – TEXT: DOUBLE-ENTRY: “Double-entry” or “Double-Keying” is a process used by operators when they need to enter important information twice. The two entries are then compared with each other to ensure that they match.

When the operator presses ENTER or navigates to the next entry, then the first entry is obfuscated. This is a safety measure for the operator so that they are not tempted to just read the value from the first entry but is forced to look at the document again to enter the second value. It is not possible to Copy / Paste the values.
NEW #543: Make it possible to forget a server. Previously, every selected MetaServer was listed in the Select Server drop-down. However, it was not possible to remove a server from that list. Now, you can right-click any of the servers and select “Forget This Server” to remove it from the list.

NEW #562: CHANGE DATA DRIVE: Modern servers have relatively small SSD drive to hold Windows and key software. The data is kept on a large secondary internal hard drive.
It is now possible to move MetaServer’s data that holds all queued documents, MetaServer databases, workflows, logs, etc. to another drive than the C drive. Typically to a larger internal hard drive. In the server tab, you have a new function called “Data Drive“. It lists all available internal drives. For each drive, you can see the total size and its free space. You can also check the space taken by MetaServer’s data folder.
You simply select the drive you want to move the data folder to and press “Move…”

A warning message will pop up:

When pressing Yes, all data will be moved. Depending on the size of your data folder, this can take some time.
At the end of the process you can decide to keep the original data folder intact or delete the files in the original data folder.
NEW #561: BOOKLET SPLITTER: Booklets or saddle stitched books can be easily produced with modern digital copiers. The copier automatically prints pages in the right sequence, folds the paper and staples the book in the middle delivering a nice booklet in the output tray.
This booklet format is often used by attorneys or notaries to produce contracts, deeds, statements or notarial acts. Also surveys, exams, admission forms etc. are often printed in booklet format.
To split the folded booklets in individual pages with MetaServer, the booklets simply need to be unstapled and unfolded. After scanning the unfolded booklets with a wide duplex scanner, you end up with A3 (297 × 420 mm) or Ledger sized images (11″x17″), in case the folded booklet is A4 or letter size, containing 4 pages per sheet (2 on the front and 2 on the back) in an awkward sequence.
MetaServer’s Split Booklets action will split the unfolded pages in two and put them in the correct sequence.
To demonstrate the Booklet Splitter, we added a new workflow called: CB – BOOKLET SPLITTER
- Samples are available in: C:\META-DEMO\MFP\BOOKLET-SPLITTER
- Copy them in: C:\META-IN\MFP\BOOKLET-SPLITTER to split them
- The result will first be displayed in the Organizer to show the result during a demo, and after approval the result will be placed in PDF format in C:\META-OUT\MFP\BOOKLET-SPLITTER

NEW #575: VRS DESKEW AND AUTO-ROTATE IS NOW INCLUDED WITH TEXT EXTRACTION: New and existing MetaServer licenses that have the Text Extraction module enabled also get access to VRS Deskew, Auto-Rotate and fixed Rotate options.
For existing MetaServer licenses, you simply have to refresh your license to enable the VRS Deskew & Rotate option. Auto-Rotating and deskewing your scanned images before extraction helps improve the OCR read rate. It is just a matter of adding a VRS action and only enable the deskew and one of the Rotate options.
Converting to black & white requires the full VRS option, so make sure that VRS is configured in color mode.
Version 3.1(6) | 2020-09-03
NEW #540: WORKFLOWS – HIGHLIGHTER TO ORGANIZE WORKFLOW ACTIONS: The Workflows tab now features a highlighter tool to mark up actions belonging to each other in the same color.

The tool is also available in the context sensitive right-click menu for each of the actions.
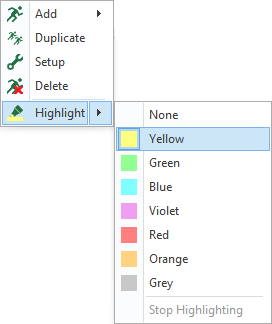
The tool is useful when working with complex workflows containing distribute trees and conditional actions.
NEW #544: CONVERT TO JPG: You can now convert any imported file format to JPG. You can also set the JPG quality level.
When importing JPGs, you also need to go through a Convert to JPG action if you want to output the processed documents (separated / rotated / blanks deleted) in JPG format. To output the processed JPGs, select Processed JPG as the File Source in your export action.
NEW #507: NEW VARIABLE { Document File Type }: this new variable can be equal to one of the following values:
– JPG
– PNG
– TIF
– PDF
– PDF AcroForm
– PDF Image
– PDF Image with Text
– PDF Text
– PDF XFA
– Unknown
You would typically use a Set Field Value rule to populate a field with the Document File Type. Next, you can use a Distribute action to handle each File Type individually.
NEW #517: EXPORT TO BOX – USE BOX ID FOR SUBFOLDER: This new option allows you to provide a direct Box subfolder ID to accelerate export to Box with structures containing 10000s of subfolders.

The subfolder ID must be contained in a MetaServer field and should be selected as the Box ID in the setup. If the Box ID does not exist, MetaServer will fall back using the subfolder structure as defined in the Name entry of the setup.
To disable the feature and define all subfolders in the Document name entry of the main setup as before, just leave the Box ID field empty.
NEW #526: EXTRACT – SUPPORT TO USE ADDITIONAL CORES: So far, MetaServer used only 1 Extraction processing queue. It is now possible to purchase additional queues to leverage systems with multiple cores and increase performance.
Tests on a quad core system tripled the Extraction speed when going from 1 Extraction queue to 4 Extraction queues.
Please note that, if you have a workflow that already uses Kofax VRS, Convert to Searchable PDF, etc. these actions were already using their own queues and consume CPU resources. This means that you won’t get the same performance increase compared to a system mainly used for Extraction of metadata.
ENHANCEMENT #558: SERVER – IMPROVED WARNINGS WHEN THE CLIENT IS NOT CONNECTED TO A METASERVER: If the user prematurely interrupts the MetaServer discovery when they open the Admin or Operator client for the first time, a warning message is displayed:

When the user opens the backstage to activate or check his license without a MetaServer connection, the activation fields are grayed out and a big red warning message indicates: “”No MetaServer connected! Please go back to the main window and select a MetaServer.”

Version 3.1(5) | 2020-07-21
This patch is automatically installed from this version on. Technically VrsSdkPatch.exe is ran automatically in quiet mode at the end of the MetaServer and Admin installation.
ENHANCEMENT: VALIDATION DEFAULTS: We changed “View” and “Zoom” defaults to “Input (manual navigation)” and “Page width” which are the most commonly used settings.
ENHANCEMENT: EXPORT TO BOX CACHE ENHANCEMENTS:
1) We now store all folders in cache during parsing even those that we don’t need for the current document
2) We now adjust the “parse item count” automatically based on what Box reports as the maximum parse count. Previously, it was set to a fixed value of 100 items, but, apparently, Box typically allows a maximum of 1000 items, reducing the number of Box calls with a factor 10.
FIX: EXPORT TO FOLDER: Previously, the Export to Folder action failed when setting the folder to a server path without subfolders.
When the export folder just contained a server name, like “\\\\LOCALHOST”, and when you exported documents in subfolders under this server path, and those subfolders already existed, then multiple copies of the same file got exported indefinitely. This has been fixed.
FIX: EXPORT TO ENADOC: The user name was not saved correctly, causing export failures.
Version 3.1(4) | 2020-07-10
NEW: EXPORT TO ENADOC: Enadoc is a cloud-based or on-premise DMS that provides user-friendly features to manage large document libraries. The key features of the solution includes enterprise search, on screen document viewers, custom metadata, ability to implement multiple security levels at user and document level, document retention policy management, records management, integration with external systems and disaster recovery capabilities.
For more info, please visit www.enadoc.com
The Export to Enadoc action allows you to export documents to a specific Enadoc library using a Tag profile of choice to set the document’s security level. It also includes the possibility to set a document link that can be shared via email (using an Export to Email action) or include as a hyperlink in a CSV, XML file or database table.

NEW: EDIT – ADD EXTERNAL DOCUMENTS: Use the Add External Documents action to append or prepend additional documents that already exist on disk to the document processed by MetaServer.
For example, you can process a check with MetaServer, read the invoice numbers covered by the check with an extract action and store them in a field called Invoice List.
Next, you use an Add External Documents action to append these invoices already stored on disk and named after their invoice number to the check.

ENHANCEMENT: KOFAX VRS: SHOW FILE SIZE BEFORE AND AFTER VRS PROCESSING: We now show the file size of the page above the viewers before (left side) and after (right side) processing.

ENHANCEMENT: EXPORT TO BOX: You can now also see the field type in the field mapping table (string, date, float or enum). If the field is of the enum type, you can also see the allowed values in Box through a drop-down.
Version 3.1(3) | 2020-06-19
You can map MetaServer fields with Box metadata attributes for precise searching. You can also generate searchable PDFs (or PDF/A) to perform a search on any word in your scanned documents stored in Box.
Once your documents reside in Box, they also become mobile. Box apps are available for Android, iOS and Windows smart phones and tablets. And if you want to store documents on your local system or server, install the Box sync software to keep a local replica of your documents as well.
We spend a lot of time optimizing the export to BOX for speed to handle large document volumes, we accomplished this by caching folder IDs and by using multiple export threads.
You can use the Box connector with any of Box’ subscription plans. However, Metadata & custom templates are only available starting from the Business Plus plan.

NEW: CONVERT – KOFAX VRS: with this new Convert action you can improve image quality. Here are some of Kofax VRS’ key functions:
Perfect Images: Get process-ready images enhancing faint text enabling better recognition and OCR extraction rates.
Color Detection: Detect and retain color in mixed batches of color and black-and-white documents without presorting. Black-and-white documents are stored as very compact files.
Automatic Deskew: Automatically crop and deskew each image based on the content of the original documents.
Auto Orientation: Automatically rotate a page that is scanned in a non-standard orientation.
Blank Page Deletion: Intelligently delete blank pages.
Hole Punch Removal: Eliminate hole punch markings with the surrounding page color.
Cloud-Friendly Images: Suppress noisy backgrounds and shaded areas, resulting in ultra-compact image files that are ideal for display and rapid retrieval over the web.
In the below screenshot, you can see Auto Orientation, Automatic Deskew, Faint Text Enhancement and Hole Punch Removal in action.

If you install MetaServer with the full installer, which you can download from the MetaServer product page, a number of demo documents will be placed in:
“C:\\META-DEMO\\MFP\\KOFAX VRS”
These demo documents are perfect to experiment with the different VRS settings.
NEW: CONVERT TO PDF/A: with the Convert to PDF/A action, you can convert standard PDF files to archivable PDF files for long-term preservation (PDF/A).

NEW: IMPORT EMAIL – DISK SOURCE: you now have two import sources in the Import Email action: IMAP and Disk. When you select Disk as a source, you can import .eml and .msg files from a watched folder instead of watching an email inbox through IMAP.
NEW: IMPORT EMAIL: Replace invalid files / password protected files with a warning image.
Before, invalid / corrupt attachments and password protected attachments were moved to the errors tab and valid attachments continued to be processed. With these new options enabled, the files will be replaced with warning images. This makes it visually clear that some attachments were corrupt or password protected.

The final PDF will look like this:

NEW: VALIDATION: HYPERLINK VALIDATION RULE: We added a new View option with the Hyperlink validation rule. This validation rule opens external files in an associated program.

In Validation, Hyperlinks show as “read only” fields with a hyperlink button. Pressing the hyperlink button opens the file in the associated program.

If the value is not a file but just a folder, then the hyperlink button will open the folder in Windows Explorer.

NEW: ORGANIZER / VALIDATE: OPEN DOCUMENT LIST – FILTER: You can now filter the documents in the document list. Just click the filter icon in the column you want to use for filtering and only check the values you want to display in the list. You can combine filters of multiple columns.

Version 3.1(2) | 2020-04-24
NEW: EXPORT TO EMAIL: INSERT IMAGES AND PAGE THUMBNAILS IN HTML EMAIL BODY: It is now possible to insert one or more pages of the document or up to 5 images from disk in the email body.
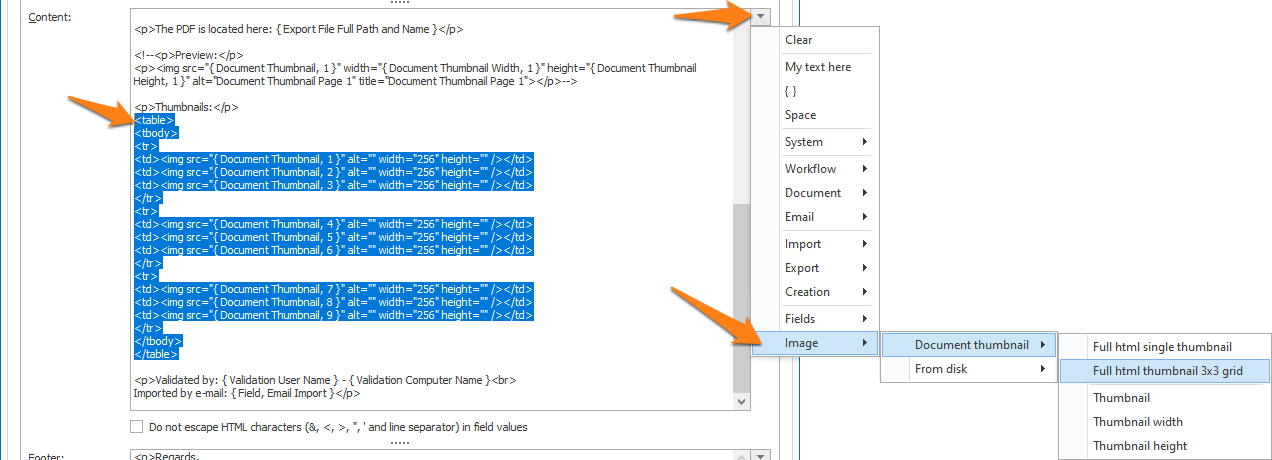
You can define the dimensions (by default, we fit the images in a 600 x 600 rectangle) of your page thumbnails and images through the Document Thumbnail or Image From disk setup.
You can use different variables in your HTML code to set the image source (page thumbnail or image from disk) and the width and height. You can also select a predefined full HTML code option to insert the correct HTML code to insert a thumbnail or image.
Document Thumbnail
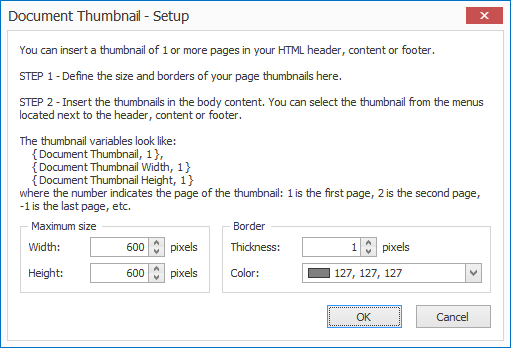
Variables for document thumbnails:
{ Document Thumbnail, 1 }
{ Document Thumbnail Width, 1 }
{ Document Thumbnail Height, 1 }
The number indicates the document’s page number for the thumbnail, so you can specify which page you want to insert as a thumbnail.
For example:
– Enter 1 for the 1st page
– Enter -1 for the last page
– Enter -2 for the page before the last page
– Etc.
You can also use the “Full HTML” option to generate the correct HTML code to insert document thumbnail of page 1. Simply change the page number if you want to display another page number:
<p>
<img src=”{ Document Thumbnail, 1 }” width=”{ Document Thumbnail Width, 1 }” height=”{ Document Thumbnail Height, 1 }” alt=”Document Thumbnail, 1” title=”Document Thumbnail, 1“>
</p>
Images from disk
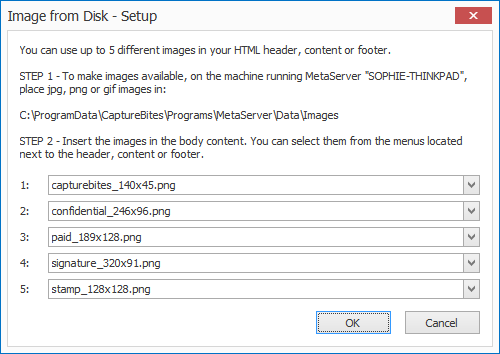
You can insert JPG, PNG, static and animated GIFs to your email body. These can be selected and mapped to the image variables during setup by first copying them to the following folder:
C:ProgramDataCaptureBitesProgramsMetaServerDataImages
Variables for images from disk:
{ Image From Disk, 1 }
{ Image From Disk Width, 1 }
{ Image From Disk Height, 1 }
The number indicates the image number.
You can also use the Full HTML option to generate the correct HTML code to insert Image From Disk, 1. Simply change the image from disk number in the HTML code if you want to display another image from disk:
<p>
<img src=”{ Image From Disk, 1 }” width=”{ Image From Disk Width, 1 }” height=”{ Image From Disk Height, 1 }” alt=”Image From Disk, 1” title=”paid stamp”>
</p>
You can also select the “Full HTML including Hyperlink” option to insert a clickable image pointing to a hyperlink:
<p>
<a title=”CaptureBites Software Development and Consulting” href=”https://www.capturebites.com/“>
<img src=”{ Image From Disk, 1 }” width=”{ Image From Disk Width, 1 }” height=”{ Image From Disk Height, 1 }” alt=”Image From Disk, 1” title=”cb logo”>
</a>
</p>
If you want to insert another image than image 1, just replace the number with the desired image number.
Version 3.1(1) | 2020-03-27
NEW: ONLINE LICENSE ACTIVATION:
IMPORTANT: After upgrading to MetaServer version 3.1.1, a pop-up window will ask you to request a serial number. If you haven’t received a serial number already, please press the “Request a Serial Number” button and fill out the form. We will send you your serial number as soon as possible.
Please also note that old MetaServer activation codes (e.g. “K-123F0-12345-123B4-CD12B-C0D12-E1EB2”) are not compatible with this version and future releases of MetaServer. You can apply for a replacement serial number through our online request form.
Previously, customers had to install MetaServer first before we could provide the activation code. With this new licensing system, the customer immediately receives a unique serial number when he orders MetaServer that he can use to activate his license.
The new licensing system features following capabilities:
1) Online Activation: Just enter the serial number and press Activate. A serial number can only be used on one machine. To reuse it, it needs to be deactivated first. A detailed guide on how to activate MetaServer can be found here.
2) Online Deactivation: liberates a license serial number so it can be used on another machine.
3) Online Refresh: the customer can order additional MetaServer modules which are linked with their existing serial number. To enable these additional modules, the customer simply needs to open the license tab and press Refresh to activate them.
4) Offline Activation: if your system does not have a network connection, you can activate / deactivate your license manually on another device with an internet connection. A detailed guide on how this works can be found here.
NEW: ORGANIZER: Organize a document before all thumbnails are created. This means that thumbnails are now only created when you need them, making it possible to interact with the document sooner.
ENHANCEMENT: FIND WORD – ACCEPT WORDS FROM DB: If you try to test a document with an empty DB table (= zero records), you get a warning message: “Rule X, Find Word with Mask / Words: Accept words from database: table ABC is empty. Please add records to your table.”

Version 3.1(0) | 2020-03-13
NEW: ONLINE LICENSE ACTIVATION: This is a limited Beta version.